For x86-64 Assembly Enthusiasts: DIY Fibers in C++
This hands-on article walks through implementing cooperative multitasking fibers from scratch using x86/x64 MASM assembly and C++, explaining every stack manipulation, register preservation rule, and ABI constraint along the way. The result is a fully working fiber scheduler that runs entirely in user space without any OS involvement.
A fiber is the smallest unit of execution that the OS kernel doesn't even see. Multiple fibers share a single OS thread and switch between each other voluntarily — no preemption, no kernel transitions, no expensive context switches. This article builds a working cooperative fiber scheduler from the ground up, explaining the x86-32 and x86-64 assembly required to make it tick.
Fibers vs. Threads
OS threads are managed by the kernel. The scheduler decides when to interrupt them, saves their registers, and resumes a different thread. This preemption is powerful but costly: each context switch crosses the user/kernel boundary and invalidates CPU caches.
Fibers are cooperative: a fiber runs until it explicitly calls yield(). This means:
- No kernel involvement — context switches stay in user space.
- The programmer chooses yield points, dramatically reducing race conditions.
- Blocking system calls (like
Sleep()) stall all fibers on the thread. - Code must be written with non-blocking I/O patterns in mind.
Basic Usage
The target API looks like this:
void __stdcall fiber1(void* data) {
for (auto i = 5; i >= 0; --i) {
std::cout << "+Fiber1:" << ::GetCurrentThreadId()
<< " " << i << std::endl;
yield();
}
}
void __stdcall fiber2(void* data) {
for (auto i = 0; i <= 5; ++i) {
std::cout << "-Fiber2:" << ::GetCurrentThreadId()
<< " " << i << std::endl;
yield();
}
}
int main() {
FiberManager fm;
fm.addFiber(fiber1, nullptr);
fm.addFiber(fiber2, nullptr);
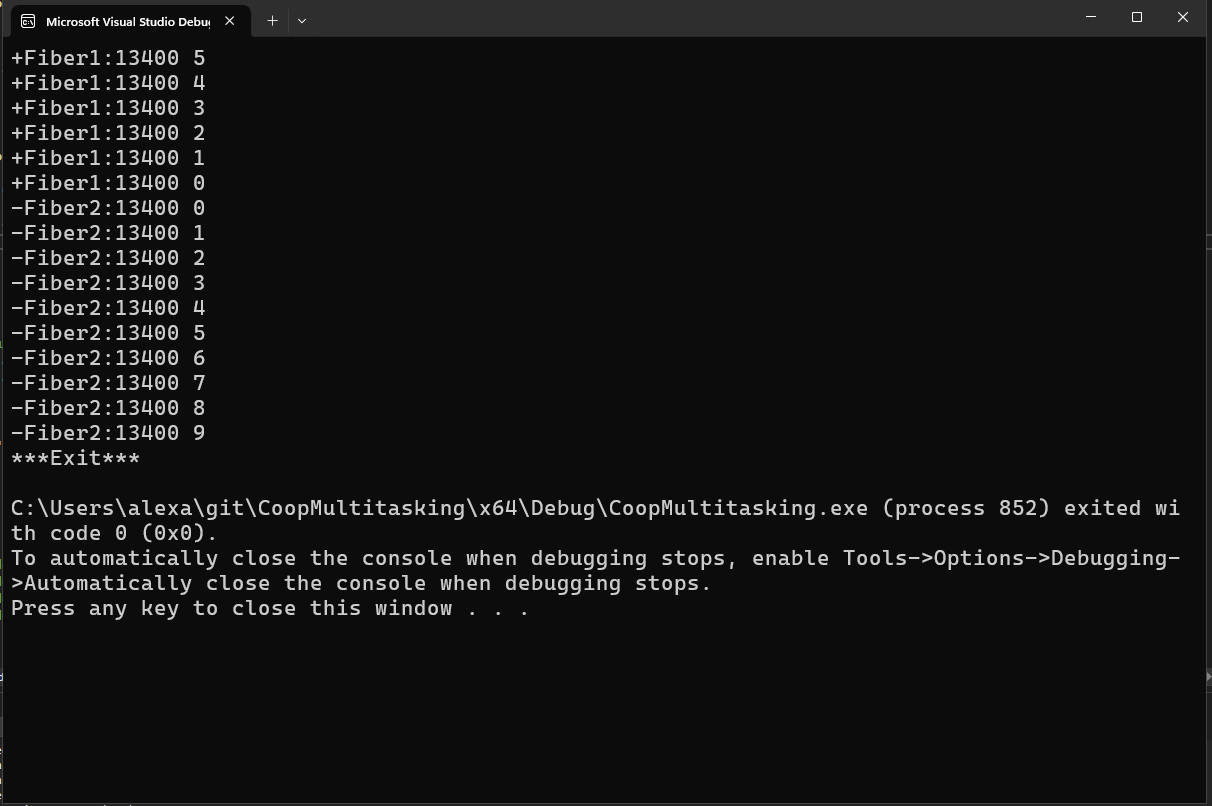
fm.run();
}Both fibers print the same GetCurrentThreadId() — proof they run on one thread. The output interleaves perfectly because each fiber yields after every iteration.
Non-Blocking Sleep
Because Sleep() blocks the entire thread, a fiber-aware sleep spins on a timer and yields on every iteration:
void mySleep(uint32_t milliseconds) {
ULONGLONG t = GetTickCount64();
while (GetTickCount64() < t + milliseconds) {
yield();
}
}While one fiber waits, all other fibers continue executing normally.
Internal Architecture
Each fiber is described by a FiberDescriptor that holds:
- A private stack — an array of 16,384 pointer-sized slots.
- A saved stack pointer (
_stackPointer) pointing to where execution was last suspended. - Methods to verify stack ownership and manage the stack pointer.
The FiberManager maintains a list of FiberDescriptor objects, a pointer to the currently running fiber, and — critically — a saved copy of the main thread's stack pointer so that control can be returned to main() when all fibers complete.
The Three Assembly Functions
The entire switching mechanism rests on three low-level functions:
1. lowLevelEnqueueFiber — Stack Initialization
Before a fiber can be resumed for the first time, its stack must look exactly as if the fiber had already been running and had just yielded. This function fabricates that initial stack state:
; 32-bit version (MASM)
lowLevelEnqueueFiber PROC
push ebp
mov ebp, esp
mov esp, [ebp + 10h] ; switch to fiber's stack (pStack)
push [ebp + 0Ch] ; push pData argument
push onFiberFinished ; push cleanup handler as return address
push [ebp + 08h] ; push fiber entry point
; reserve space for non-volatile registers (EBX, EBP, EDI, ESI)
sub esp, 10h
mov eax, esp ; return new stack pointer in eax
mov esp, ebp
pop ebp
ret
lowLevelEnqueueFiber ENDPThe layout pushed onto the fiber's stack (from top to bottom) is: space for non-volatile registers → fiber entry point → onFiberFinished handler → pData argument.
2. yield() — Saving Context and Switching
When a fiber calls yield(), the assembly saves all non-volatile registers onto the current stack, then transfers to the C++ function fiberManagerYield():
; 32-bit
yield PROC
push ebx
push ebp
push edi
push esi
call fiberManagerYield ; C++ picks next fiber and calls lowLevelResume
pop esi
pop edi
pop ebp
pop ebx
ret
yield ENDPfiberManagerYield() (C++) saves the current stack pointer into the current fiber's descriptor, selects the next fiber from the queue, and calls lowLevelResume() with the next fiber's saved stack pointer.
3. lowLevelResume() — Restoring Context
; 32-bit
lowLevelResume PROC
mov esp, [esp + 4] ; switch to target fiber's stack
pop esi
pop edi
pop ebp
pop ebx
ret ; jumps to wherever the target fiber last yielded
lowLevelResume ENDPThe ret instruction pops the return address that yield() pushed — which is the instruction immediately after the call yield in the fiber's code. Execution resumes exactly where the fiber was suspended.
Fiber Completion
When a fiber function returns normally, the C++ ret pops the onFiberFinished address that was pre-loaded onto the stack during initialization. This cleanup handler:
- Removes the completed fiber from the manager's list.
- Selects the next runnable fiber.
- If no fibers remain, restores the main thread's original stack pointer and returns to
main().
32-bit vs. 64-bit: Key Differences
The 64-bit implementation follows Microsoft's x64 fastcall ABI, which introduces several additional requirements:
Register usage:
- First four integer arguments:
RCX,RDX,R8,R9(instead of the stack). - Return value:
RAX. - Non-volatile registers:
RBX,RBP,RDI,RSI,R12–R15,XMM6–XMM15— all must be saved and restored.
Shadow space: The caller must allocate 32 bytes below the return address before every call. The callee may use this space freely. This must be synthesized when setting up a fiber's initial stack:
mov rsp, r8 ; switch to fiber's stack
sub rsp, SHADOWSIZE ; allocate 32-byte shadow space
alignstack ; macro: align RSP to 16 bytesStack alignment: The stack pointer must be 16-byte aligned at every call instruction. The alignstack macro rounds down RSP:
alignstack macro
and rsp, -10h
endm64-bit immediates: push imm64 does not exist in x86-64. To push a 64-bit address (like the onFiberFinished handler), use an intermediate register:
mov r8, onFiberFinished
push r8Fiber entry proxy: In 64-bit mode, arguments are passed in registers, not on the stack. A small fiberEntry trampoline pops them off the pre-loaded stack and places them in the correct registers before jumping to the actual fiber function:
fiberEntry PROC
pop rdx ; target function address
pop rcx ; pData argument
enter SHADOWSIZE, 0
alignstack
call rdx ; call the actual fiber
leave
ret ; hits onFiberFinished
fiberEntry ENDPXMM register saving: Non-volatile XMM registers must also be preserved. A helper macro stores 128-bit registers onto the stack:
pushmmx macro mmxreg
sub rsp, 16
movdqu [rsp], mmxreg
endm
popmmx macro mmxreg
movdqu mmxreg, [rsp]
add rsp, 16
endmGetting the Current Stack Pointer
A small helper exposes RSP / ESP to C++ for stack depth calculations:
; 32-bit
lowLevelGetCurrentStack PROC
mov eax, esp
ret
lowLevelGetCurrentStack ENDP
; 64-bit
lowLevelGetCurrentStack PROC
mov rax, rsp
ret
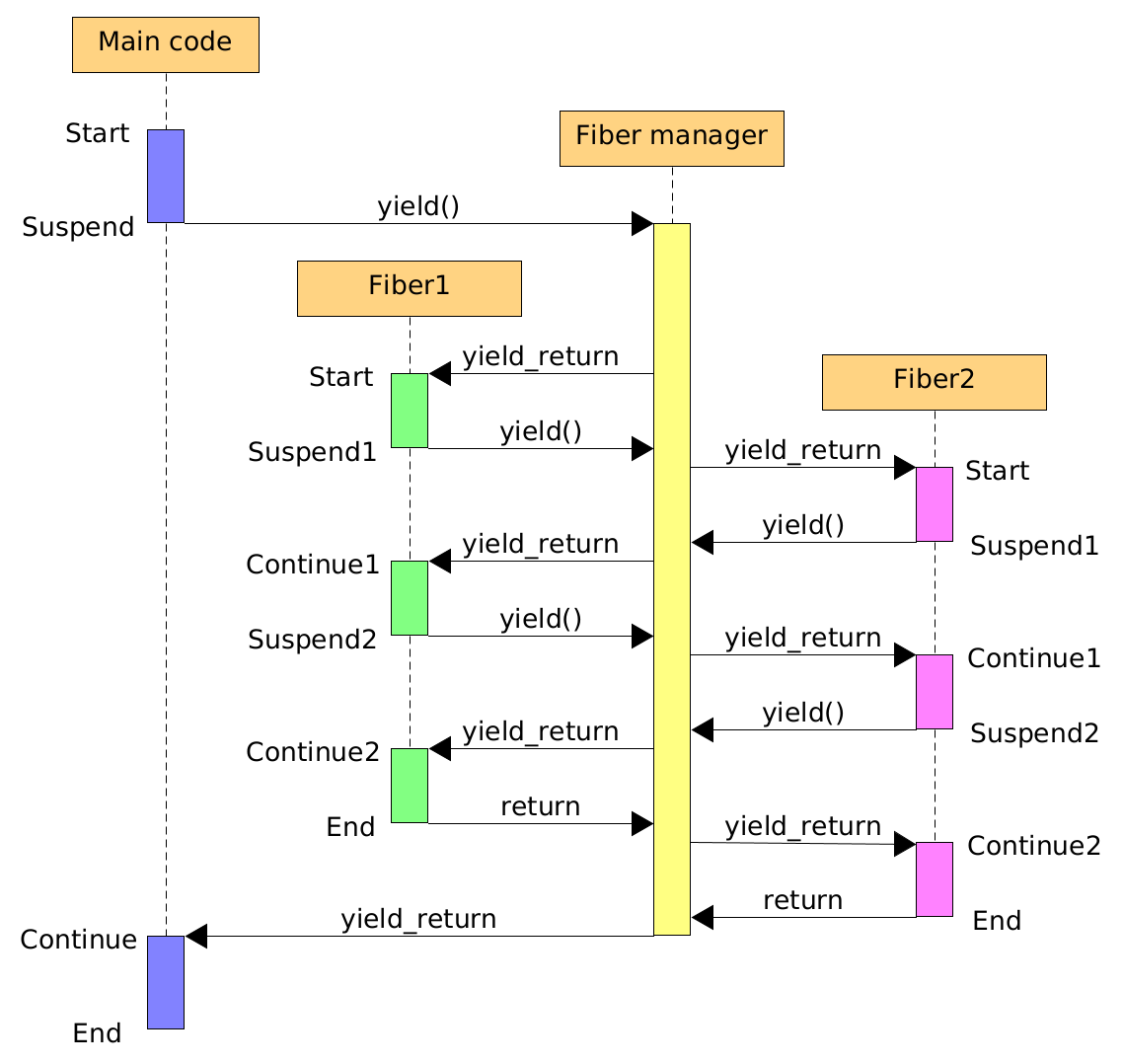
lowLevelGetCurrentStack ENDPFull Execution Flow
Putting it all together, a single yield/resume cycle proceeds like this:
- Fiber A calls
yield(). yield()(assembly) pushes non-volatile registers onto Fiber A's stack.yield()callsfiberManagerYield()(C++).- The manager saves Fiber A's current
RSPinto A's descriptor. - The manager picks the next fiber (Fiber B) and calls
lowLevelResume(rsp_B). lowLevelResume()loadsRSPfrom Fiber B's descriptor.- The assembly pops Fiber B's non-volatile registers.
retpops Fiber B's saved return address — resuming it exactly where it last calledyield().


Practical Considerations
The system avoids expensive kernel transitions and simplifies synchronization in many cases, but it requires discipline:
- Every potentially blocking call must be replaced with a yielding loop.
- Stack depth must be monitored — each fiber has a fixed-size private stack.
- The system is single-threaded; true parallelism requires separate fiber schedulers on separate OS threads.
Source Code
The complete, buildable implementation is available at https://github.com/galilov/CoopMultitasking. It has been tested with Visual Studio 2022 Community and Visual Studio 2019. To enable MASM support, open the project properties and set Build Customizations → masm to enabled.
The code is provided as an educational resource without warranties. The focus is on explaining mechanisms — production fiber libraries (like Boost.Fiber or Windows fibers via ConvertThreadToFiber) add additional robustness that is beyond this article's scope.
FAQ
What is this article about in one sentence?
This article explains the core idea in practical terms and focuses on what you can apply in real work.
Who is this article for?
It is written for engineers, technical leaders, and curious readers who want a clear, implementation-focused explanation.
What should I read next?
Use the related articles below to continue with closely connected topics and concrete examples.





