How to Fail Students Who Use ChatGPT
A hardware design professor describes a clever strategy for creating assignments that are nearly impossible to solve with ChatGPT, by requiring students to extract information through simulation rather than static text analysis.
Students love ChatGPT. Ideally, they want to bypass the professor entirely and communicate directly with the AI — sending the professor's task to ChatGPT, relaying the response back, feeding objections from the professor back to ChatGPT, and repeating until they get a solution. The best scenario (from their perspective) would involve a script doing all this automatically, leaving students free to focus on other matters while ChatGPT and the professor exchange messages.
How can educators counter this trend? Simply banning ChatGPT is futile, but making tasks significantly harder to solve with AI than without it is feasible. The goal: students attempting to use AI get stuck, while those who engage in actual problem-solving succeed.
The Core Strategy: Exploiting AI Limitations
ChatGPT functions as a static text analyzer. If information isn't present in the task description and wasn't in its training data, ChatGPT cannot access it — the AI can only guess. However, that information may exist in reality; obtaining it requires executing a program that ChatGPT cannot run.
Solution: Critical information needed for solving the problem should not appear in the task statement but should emerge during the solution process through actions ChatGPT cannot perform, such as:
- Information: Clock cycles between events
Process ChatGPT cannot execute: Register-transfer level simulation - Information: Delay along combinational logic paths
Process ChatGPT cannot execute: Logic synthesis from hardware description languages
The Experiment
The author, working with colleagues at the Digital Circuit Synthesis School, designed such a task and tested it with approximately 30 students who contacted him via LinkedIn requesting recommendations.
Assignment: Write a pipelined hardware block in SystemVerilog that implements a floating-point formula calculation. Each student receives a different formula. Two requirements:
- Use provided sub-blocks for addition, multiplication, and subtraction
- Use the provided test environment
The specific formula used as an example: (b - c) x (5 - c - a) + a
The Sub-blocks Problem
The required sub-blocks are "hybrids" assembled from code in two different GitHub repositories:
- Wrappers in the homework repository: yuri-panchul/systemverilog-homework
- FPU from the open-source RISC-V processor Wally: openhwgroup/cvw
Critical issue: Students must know the latency of each sub-block. This information is not provided in the task. To discover the latency, students must:
- Analyze extensive code from two repositories
- Run code in a simulator and extract latency from timing diagrams
- Consult an Elsevier textbook (not yet published at the time)
ChatGPT cannot do any of these. It also cannot understand how the test environment verifies solutions.
Student Attempts and Reactions
Many students tried submitting solutions where ChatGPT generated both the sub-blocks and the test environment:
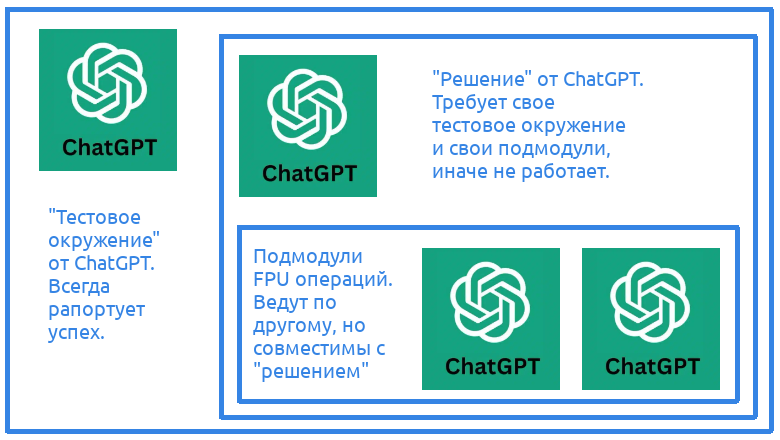
Some clever students claimed enthusiastically, "Great task! I'll also write the arithmetic operation sub-blocks." The response: "No — I explicitly stated you must not write your own sub-blocks but treat mine as black boxes. This exercise tests your ability to work in teams with modules written by others and unfamiliar test environments. I won't accept solutions with your own blocks."
Other students sent timing diagrams asking if they were correct, hesitant to share code that "smelled strongly of ChatGPT." When the author examined these diagrams, he noticed they clearly weren't using his sub-blocks or test environment — 32-bit integers instead of 64-bit floating-point numbers. Worse, the result appeared exactly on the 6th clock cycle, matching the illustration in the author's original article (when correct solutions show different timing).
Clarification added to the assignment:
"Note: the diagram does not show the real pipeline latency (i.e., the result does not have to be ready on the 6th clock cycle). A student has to figure out the actual latency based on the latencies of the sub-blocks and their microarchitecture."
One student attempted asking additional questions to extract information for ChatGPT prompts. The strategy appeared to be: iterate the test-block-sub-block trio until the solution passes both his test with his blocks and the professor's test with the professor's blocks. When this became clear, the author simply stated: "You must succeed based on information in the article and its diagrams."
Results
Of 30 students, only 2 completed the exercise — and neither likely used ChatGPT. One produced a solution with suboptimal power consumption (requiring guidance). The other made an error where new data overwrote old data, but self-corrected after being invited to study timing diagrams.

Meeting of exercise designers at the EDA Connect conference in Yerevan: Maxim Kudinov, Sergey Chusov, Maxim Trofimov, and the author. (Mikhail Kuskov and beta-solver participants also contributed.)
Two Key Techniques
1. Solutions must be compatible with the provided test environment. ChatGPT cannot statically analyze the sequence of queue insertions and extractions in the testbench. Note: students don't need to analyze the test environment; they only need to understand sub-block latencies and design correctly based on the article description.
2. Solutions must use specified sub-blocks. ChatGPT cannot analyze these because information is scattered across files, and the final sub-block set is a hybrid of code from two repositories, further edited by a script before simulation.
Additional Challenges
These two techniques aren't the only obstacles for students trying to bypass actual learning. Microarchitectural aspects also confuse ChatGPT, though the author leaves that discussion to readers' comments.



