Possibly the Most Brilliant Python Code: Analyzing Andrej Karpathy's 200-Line MicroGPT
A deep dive into Andrej Karpathy's 200-line pure Python implementation of a GPT-like transformer model with no external dependencies, breaking down its autograd engine, attention mechanism, and training loop to show how the core mechanics of ChatGPT work at the smallest possible scale.
Andrej Karpathy is one of the co-founders of OpenAI, former head of AI at Tesla, and the author of some of the most popular machine learning courses in the world. When people like him write code, it is worth paying attention to. Recently, Karpathy published a single Python file containing roughly 200 lines of code that implements a complete GPT-like transformer language model from scratch, with no external libraries whatsoever. Let us take it apart piece by piece.

What Is This?
MicroGPT is an educational "art project" — a GPT-2-like model implemented entirely in pure Python. No PyTorch, no NumPy, no external dependencies at all. Everything, from automatic differentiation to the transformer architecture, is written from scratch in about 200 lines. The goal is to show that there is nothing magical about large language models: the fundamental mechanism is the same whether you have 4,000 parameters or 400 billion.
Dataset
The model trains on approximately 32,000 human names, one per line, from a text file. Each name is treated as a "document." This is the same principle behind ChatGPT: your entire dialogue is just a "document" of a particular kind. The model learns to predict the next character in a sequence, eventually generating plausible new names that never existed.
Tokenizer
Instead of the subword-level tokenization (BPE) used by production models, microGPT uses a character-level tokenizer. Each unique character receives a numeric ID (0 through 25 for a–z), plus a special BOS (Beginning of Sequence) token. The total vocabulary is just 27 tokens. In contrast, GPT-4's vocabulary contains around 100,000 subword tokens.
Autograd Engine
The heart of training any neural network is automatic differentiation. Karpathy implements a Value class in roughly 24 lines of code that tracks:
- The forward pass result (the computed value)
- Local gradients (partial derivatives for each operation)
- Child nodes in the computation graph
Every arithmetic operation — addition, multiplication, exponentiation, logarithm — is overloaded to build a computation graph automatically. The backward() method then applies the chain rule recursively, propagating gradients from the loss all the way back to the model parameters. This is the same principle behind PyTorch's autograd, just stripped down to the bare essentials.
The key operations implemented in the Value class include:
__add__— addition with gradient: d(a+b)/da = 1, d(a+b)/db = 1__mul__— multiplication with gradient: d(a*b)/da = b, d(a*b)/db = a__pow__— exponentiation with gradient: d(a^n)/da = n * a^(n-1)log()— logarithm with gradient: d(log(a))/da = 1/aexp()— exponential with gradient: d(exp(a))/da = exp(a)
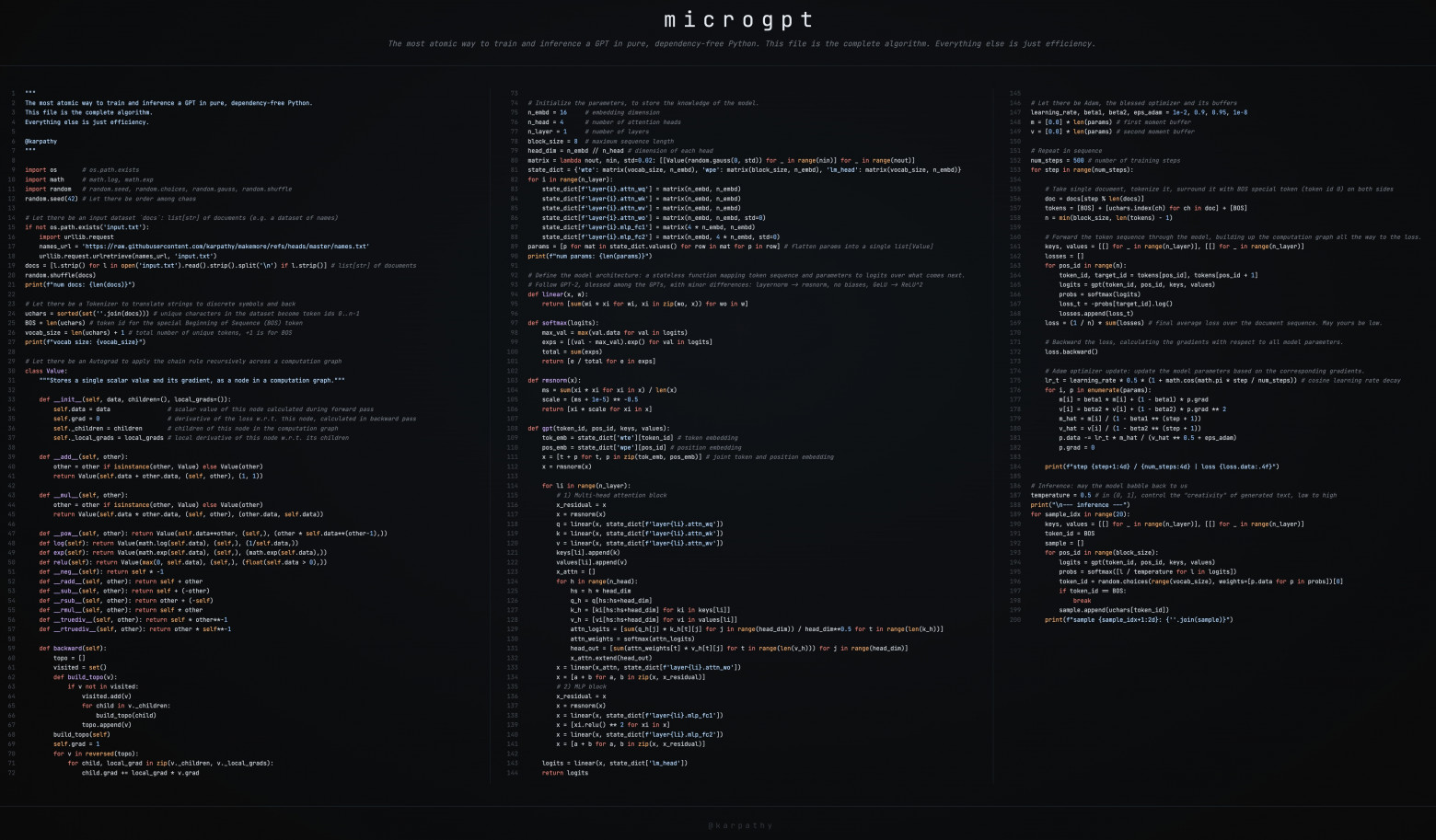
Model Architecture
The gpt() function implements the full transformer architecture in miniature:
Embeddings: Two embedding tables — one for tokens and one for positions — are combined. Each token is represented by a vector that encodes both "what it is" and "where it is" in the sequence.
Multi-Head Attention: This is the mechanism that allows tokens to "communicate" with each other. Each attention head computes Query, Key, and Value projections. The attention score between two tokens is the dot product of the query of one and the key of the other, scaled by the square root of the head dimension. A causal mask ensures that each token can only attend to tokens at earlier positions (no peeking into the future). The model uses 4 attention heads with a head dimension of 16.
MLP Block: After attention, each token passes through a feed-forward network that expands the representation by a factor of 4 and then projects it back down. This gives the model capacity to learn complex nonlinear transformations.
RMSNorm: Instead of the more common LayerNorm, the model uses Root Mean Square Normalization, which is simpler and has become popular in modern architectures (e.g., LLaMA).
Residual Connections: Each sub-layer (attention and MLP) has a skip connection that adds its input to its output. This is critical for training deep networks because it provides a direct gradient pathway.
The total parameter count is approximately 4,192. For comparison, GPT-2 has 1.6 billion parameters and GPT-4 is estimated to have over 1 trillion.
Training Loop
Training follows the standard recipe:
- Select a random document (name) from the dataset
- Tokenize it and prepend the BOS token
- Run the forward pass through the model
- Compute cross-entropy loss: for each position, measure how surprised the model was by the actual next token
- Run
loss.backward()to compute gradients via backpropagation - Update parameters using the Adam optimizer with learning rate decay
The loss starts at approximately 3.3 (equivalent to random guessing across 27 tokens, since ln(27) ≈ 3.3) and decreases to about 2.37 over 1,000 training steps. This means the model has learned some structure, though it is far from perfect given the tiny scale.
Inference
After training, the model generates new names by:
- Starting with the BOS token
- Running a forward pass to get a probability distribution over the next token
- Sampling from this distribution (using a temperature parameter of 0.5 to control creativity — lower temperature means more conservative, higher means more random)
- Appending the sampled token and repeating until BOS appears again (signaling end of sequence)
Sample generated names include: "kamon," "karai," "vialan," "sher," "jede," "aliede." These are not real names but are phonetically plausible, showing the model learned the statistical patterns of human naming.
From MicroGPT to ChatGPT: What Changes at Scale
The article provides a thorough comparison of what differs between this 200-line toy and a production LLM:
Data: 32,000 names → trillions of tokens scraped from the entire internet. The training data for modern LLMs includes books, code, scientific papers, web pages, and conversations.
Tokenizer: Character-level (27 tokens) → subword encoding via BPE with ~100,000 tokens. Subword tokenization is far more efficient because common words become single tokens while rare words are broken into pieces.
Hardware: Python scalar operations on a single CPU → massively parallel tensor operations on thousands of GPUs/TPUs. Frameworks like PyTorch, optimized CUDA kernels like FlashAttention, and distributed training systems replace the handwritten Python loops.
Model Size: ~4,000 parameters → hundreds of billions of parameters. More layers, wider layers, more attention heads.
Architecture Enhancements: Production models add RoPE (Rotary Position Embeddings) instead of learned position embeddings, Grouped Query Attention (GQA) for memory efficiency, Gated Linear Units (GLU) in the MLP blocks, and sometimes Mixture-of-Experts (MoE) layers for conditional computation.
Post-Training: MicroGPT has none. Production models undergo Supervised Fine-Tuning (SFT) on curated instruction-response pairs and Reinforcement Learning from Human Feedback (RLHF) to align the model with human preferences and safety requirements.
Key Insight
The fundamental mechanism has not changed: predict the next token, sample it, repeat. Everything else — the massive datasets, the GPU clusters, the RLHF pipeline, the safety filters — is optimization and scaling on top of this core loop. MicroGPT makes this viscerally clear.
Learning Path
Karpathy structured the code as a progressive learning exercise via revisions in his GitHub gist:
train0.py— Frequency-based bigram model (no neural network)train1.py— MLP-based bigram modeltrain2.py— Custom autograd enginetrain3.py— Single-head attentiontrain4.py— Multi-head attentiontrain5.py— Adam optimizer (final version)
Each step adds exactly one new concept, making it possible to follow the entire evolution from a simple character frequency table to a full (tiny) transformer.
FAQ
Does the model actually understand language? No. It outputs statistically probable continuations based on patterns learned from training data. There is no semantic understanding, only sophisticated pattern matching.
What are hallucinations? When a model generates text that is plausible-sounding but factually incorrect. This happens because the model maximizes the probability of the next token, not the truthfulness of the statement.
How does a ChatGPT conversation work? Your entire chat history is formatted as a single document. Each time you send a message, the model receives the full conversation so far and generates the next tokens to continue it.



