I Replaced Google with 50 Lines of Python
A DevOps engineer with a decade of experience built a minimal Python script that converts natural-language requests into bash commands using an LLM — and after a month of use, started forgetting how to write tar -xzf from memory. The productivity gain is real. So is the cognitive cost.
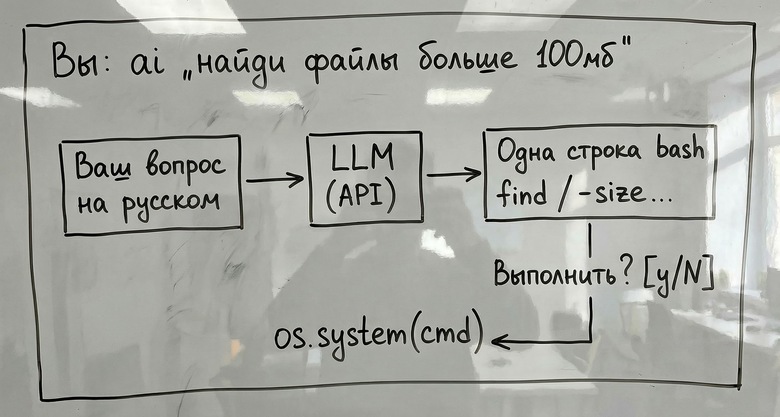
I have been working in DevOps for ten years. I know Linux well. And yet I have searched for "tar extract" 47 times this year. "Crontab format" — 22 times. "Kill process on port" — 28 times. The syntax simply refuses to stick in long-term memory, and every time I need it I am back in a browser tab.
So I built a tool to stop doing that. It turned out to be about 50 lines of Python. A month later, I am starting to wonder what I have done to myself.
The Script
The idea is simple: describe what you want in plain language, get back a single bash command, approve it, and it runs. No external dependencies — only the Python standard library. Works with OpenAI's API or a local Ollama instance.
#!/usr/bin/env python3
"""ai-bash: ask in plain language, get bash"""
import sys, os, json, urllib.request
API_KEY = os.getenv("OPENAI_API_KEY", "")
API_URL = os.getenv("AI_BASH_URL",
"https://api.openai.com/v1/chat/completions")
MODEL = os.getenv("AI_BASH_MODEL", "gpt-4o-mini")
SYSTEM = (
"You are a terminal assistant. The user describes a task "
"in plain language. Reply ONLY with a bash command — one line. "
"No explanations, no markdown, no backticks. "
"Multiple commands: use && or |. OS: Linux."
)
def ask(question: str) -> str:
body = json.dumps({
"model": MODEL,
"temperature": 0,
"max_tokens": 200,
"messages": [
{"role": "system", "content": SYSTEM},
{"role": "user", "content": question},
],
}).encode()
req = urllib.request.Request(API_URL, data=body, headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}",
})
with urllib.request.urlopen(req) as r:
data = json.loads(r.read())
return data["choices"][0]["message"]["content"].strip()
def main():
if len(sys.argv) < 2:
print("Usage: ai 'find files larger than 100mb'")
sys.exit(1)
cmd = ask(" ".join(sys.argv[1:]))
print(f"\n \033[1;33m➡ {cmd}\033[0m\n")
if input("Execute? [y/N] ").strip().lower() in ("y",):
os.system(cmd)
if __name__ == "__main__":
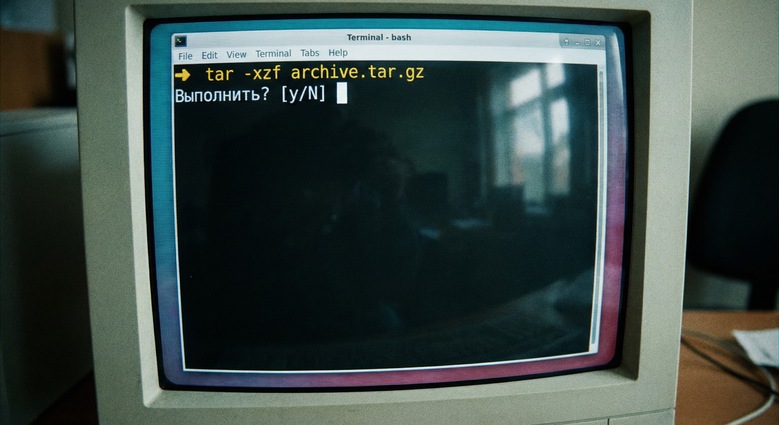
main()The confirmation prompt before execution is not optional — it is the most important line in the script. More on that shortly.
One Month of Real-World Data
After 30 days of daily use:
- 847 requests processed — an average of 28 per day.
- $1.80 in API costs via OpenAI. Free with local Ollama.
- 2.7% error rate — 23 responses that were wrong or incomplete.
- 3 dangerous commands caught and stopped by the confirmation step.
Examples that worked well:
- "rename all .jpeg to .jpg" — returned the correct bash parameter expansion command.
- "kill the process using port 8080" — returned the correct
lsofpipeline.
The Three Near-Disasters
Those three dangerous commands were not edge cases — they were reasonable-sounding queries that produced genuinely harmful output:
rm -rf /tmp/*— would have deleted critical Unix socket files that active services depended on.find /var/log -mtime +7 -delete— missing the-type fflag; would have deleted directories as well as files.chmod -R 777 .— would have broken SSH key permissions and locked me out of the server.
After these incidents I added a blacklist for known dangerous patterns and an --explain mode that asks the model to describe what the command does before I decide whether to run it.
The Uncomfortable Side Effect: Knowledge Degradation
Here is the part I did not expect. Commands I used to "almost remember" have degraded. What was once an instant recall — a 0-second retrieval — has become a 10-to-20-second delay, or in some cases complete amnesia. The command is just gone, and I reach for the tool.
The brain appears to have made a rational decision: why maintain in long-term memory something that is retrievable in two seconds? The storage cost exceeds the retrieval cost, so it outsources.
Forgetting a phone number is one thing — that is pure data. Forgetting tar -xzf is different. That is a piece of operational knowledge tied to doing the job. And I am now dependent on a working internet connection — or a running local model — to access it.
The question that keeps occurring to me: when do I stop being an engineer who uses tools and become an operator who is useless without them?
The Honest Verdict
The productivity gain is genuine. The cognitive cost is also genuine. This is not a tool I would recommend blindly — it requires discipline about what you confirm and an honest accounting of what you are trading away.
The confirmation prompt is doing more work than it looks like. Use it.



