Running Real DeepSeek R1 671B on a Gaming PC — and Testing It on a 160k-Token Context
A hands-on experiment running the full 671-billion-parameter DeepSeek R1 model on consumer hardware — an i7-14700, 192 GB DDR5 RAM, and a single RTX 4090 — using aggressive IQ1_S_R4 quantization. The model maintains coherent reasoning even at the maximum 160k-token context window.
Almost all mainstream local models are launched in essentially the same way. This article focuses on running the full DeepSeek R1 671B model on consumer hardware and explores whether it stays coherent at very large context sizes — specifically 160,000 tokens, the model's published maximum.
Hardware Used
- CPU: Intel Core i7-14700 (20 cores)
- RAM: 192 GB DDR5 at 4800 MT/s (4 × 48 GB)
- GPU tested separately: RTX 4090 (24 GB VRAM) and RTX 4060 Ti (16 GB VRAM)
The Core Tool: ik_llama.cpp
The standard inference engine for quantized models is llama.cpp, which uses the GGUF format. For this experiment the author uses ik_llama.cpp — a fork that significantly improves CPU performance and adds specific optimisations for Mixture-of-Experts (MoE) architectures like DeepSeek R1.
The Key Technique: Selective Tensor Offloading (-ot)
The breakthrough that makes this setup feasible is the -ot (override-tensor) parameter. DeepSeek R1 is a MoE model: at any given step only a small subset of its expert networks are activated. This creates a natural split:
- GPU: Attention tensors — lightweight, used on every single forward pass.
- CPU: FFN expert weights — very large, but each expert is accessed variably across tokens.
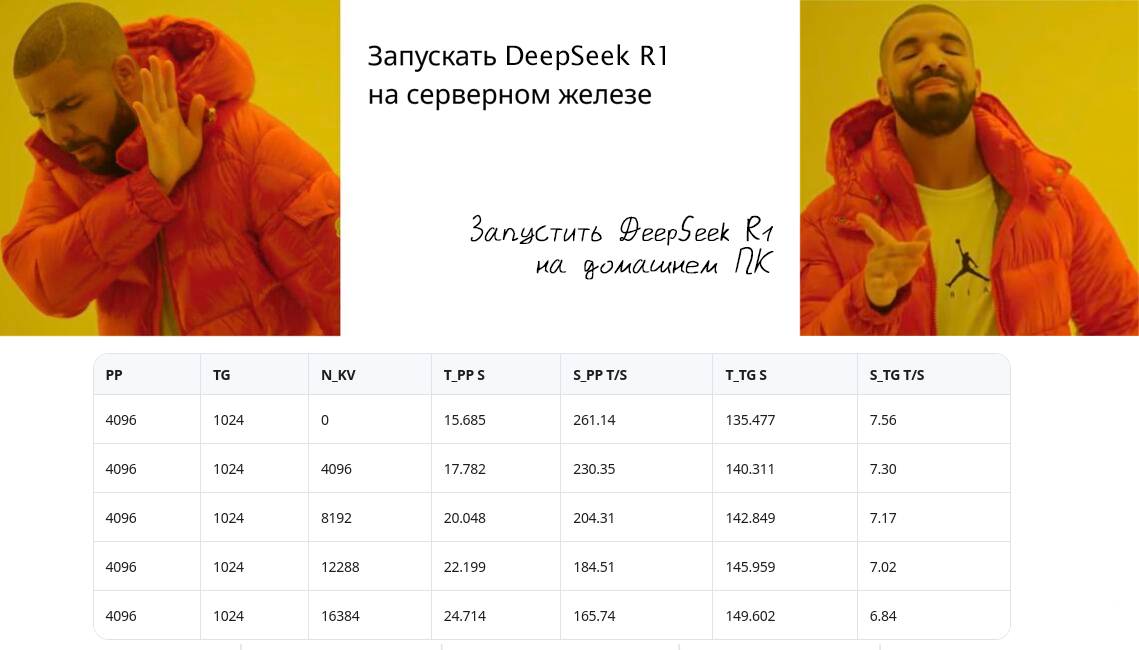
This hybrid placement doubles generation speed compared to a pure CPU run, achieving roughly 7 tokens per second.
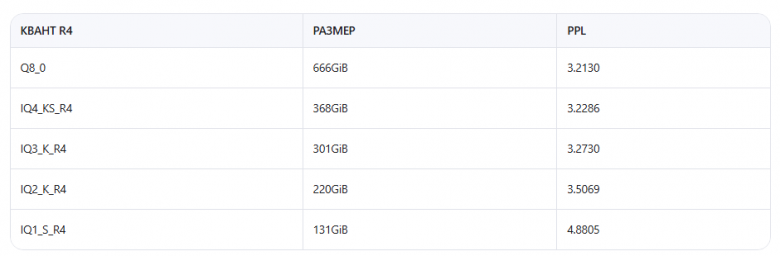
The Quantization: IQ1_S_R4 at 130 GB
The full-precision DeepSeek R1 model requires roughly 1.3 TB of storage. The IQ1_S_R4 quantization compresses it to approximately 130 GB — about a 10× reduction — while preserving more quality than simpler 1-bit schemes thanks to a refined rounding strategy. The author measures quality using KL Divergence (KLD) rather than perplexity, because KLD compares the full output probability distribution token-by-token rather than averaging across the sequence, making it more sensitive to subtle degradation.
Multi-Head Latent Attention (MLA)
DeepSeek R1 uses Multi-Head Latent Attention, which compresses the KV-cache by approximately 25× with no measurable quality loss. This is critical: without MLA, the KV-cache alone for a 160k-token context would consume tens of gigabytes of VRAM, making the experiment impossible on consumer hardware.
- RTX 4090: supports up to 80k context at 200–300 tokens/sec prefill speed
- RTX 4060 Ti: supports up to 32k context at around 60 tokens/sec prefill speed
Building ik_llama.cpp
Single GPU build:
cmake -B ./build -DGGML_CUDA=ON -DGGML_BLAS=OFF
cmake --build build --config Release -j28Multi-GPU build with MoE optimisations:
cmake -B ./build -DGGML_CUDA=ON -DGGML_BLAS=OFF \
-DGGML_SCHED_MAX_COPIES=1 -DGGML_CUDA_IQK_FORCE_BF16=1
cmake --build build --config Release -j28Launch Command
./llama-server \
-m "DeepSeek-R1-0528-IQ1_S_R4-00001-of-00003.gguf" \
-mla 3 -fa \
-ctk q8_0 \
-amb 512 \
-fmoe \
-ot exps=CPU \
-ngl 99 \
-b 4096 -ub 4096 \
-t 20 \
-c 163840Key flags explained:
-mla 3— enable Multi-Head Latent Attention with absorption mode 3-fa— Flash Attention for reduced VRAM usage-ctk q8_0— quantize the KV-cache to 8-bit to save VRAM-fmoe— enable fused MoE kernel for faster expert dispatch-ot exps=CPU— place all expert tensors on the CPU-ngl 99— offload all non-expert layers to GPU-c 163840— 160k token context window
Real-World Context Test: A Full Novel
To validate long-context coherence, the author loaded the entire Russian fantasy novel Labyrinth of Reflections (Лабиринт Отражений) by Sergei Lukyanenko — roughly 215,000 tokens — into the model's context. The quantized model was asked questions about passages from the middle of the book, character arcs, and plot details spanning the full narrative.
Results were impressive: the model accurately quoted passages from the middle of the book, correctly described character development across the entire story, and maintained factual consistency despite the 100k+ token context. Degradation only appeared when a rolling-buffer context shift was forced, causing the model to lose access to earlier text and begin fabricating citations.
Comparative Models Tested
DeepSeek V3 (Lighter Alternative)
An IQ1_S_R4 quantized version of DeepSeek V3 is available and fits in less RAM, but shows noticeably degraded KLD metrics compared to R1. For long-context reasoning tasks, R1 remains the better choice.
Llama 4 Maverick (MoE, 401B total / 17B active)
Llama 4 Maverick also uses a MoE architecture and supports up to 215k tokens via Sliding Window Attention (SWA). It maintains accuracy through 70k-token tests but shows degradation when queries reference text beyond the attention window — a fundamental limitation of the SWA design.
Gemma 3 27B (Dense Model)
A dense (non-MoE) model tested for comparison. Gemma 3 27B performs poorly on long contexts: it begins looping at 32k+ tokens and requires aggressive KV-cache quantization just to run. It is not suitable for 100k+ context tasks despite advertising SWA support.

Performance Summary
- Generation speed (hybrid CPU+GPU): ~7 tokens/sec
- Prefill speed on RTX 4090 with batch 4096: 200–300 tokens/sec
- Generation speed at 160k context (CPU-bound): ~0.5 tokens/sec
- Memory bottleneck: DDR5 at 4800 MT/s provides ~70 GB/s bandwidth; 100+ GB/s would noticeably improve throughput
Tools for Less Technical Users
- LM Studio — graphical interface, the easiest starting point
- Jan — OpenAI API-compatible desktop client
- text-generation-webui (oobabooga) — advanced parameter control, supports the
-otoverride-tensor feature
Conclusion
Even at the maximum 160k-token context, the aggressively quantized IQ1_S_R4 version of DeepSeek R1 responds coherently. The combination of MoE architecture, Multi-Head Latent Attention, and selective tensor offloading makes running a 671B-parameter model on consumer hardware not just possible, but practically useful. The experiment exceeded expectations: 192 GB of DDR5 RAM plus a single consumer GPU is enough to have a capable reasoning model available locally.



