Sharded Does Not Mean Distributed: What You Need to Know When PostgreSQL Is No Longer Enough
An in-depth analysis of why sharded PostgreSQL solutions like Citus do not provide the same ACID guarantees as truly distributed databases, and why the cost of distributed transactions may be worth paying.
A year ago, we published an article titled "When One Postgres Isn't Enough: Comparing Performance of PostgreSQL and Distributed Databases." PostgreSQL demonstrated exceptional performance in scenarios without high requirements for availability and data durability. We called this configuration "non-fault-tolerant and fantastically fast PostgreSQL." However, when write-ahead log (WAL) and replication are enabled, performance drops significantly. Replication can become a bottleneck that limits vertical scaling.
In TPC-C benchmark results, "fault-tolerant PostgreSQL" exceeded the distributed database YDB by only 5% in throughput (tpmC), yet had noticeable latency problems.
We expected discussion about PostgreSQL configuration and comparison methodology. Instead, the main debate centered on the claim that PostgreSQL scales only vertically and that Citus-like solutions do not guarantee ACID for multi-shard transactions.
There are certain misconceptions surrounding sharding, two-phase commit (2PC), and distributed transactions. For instance, it is not obvious that 2PC provides only atomicity but not transaction isolation.
Sharding a Monolith
At the core of most sharded PostgreSQL solutions lies a simple idea: instead of one instance, you use N instances, each responsible for a specific range of table keys. A routing layer (coordinator) manages these ranges and becomes the entry point for users. This layer can be on the server side (like Citus) or part of the client application.
The key point: The N PostgreSQL instances do not know about each other and do not interact with one another.
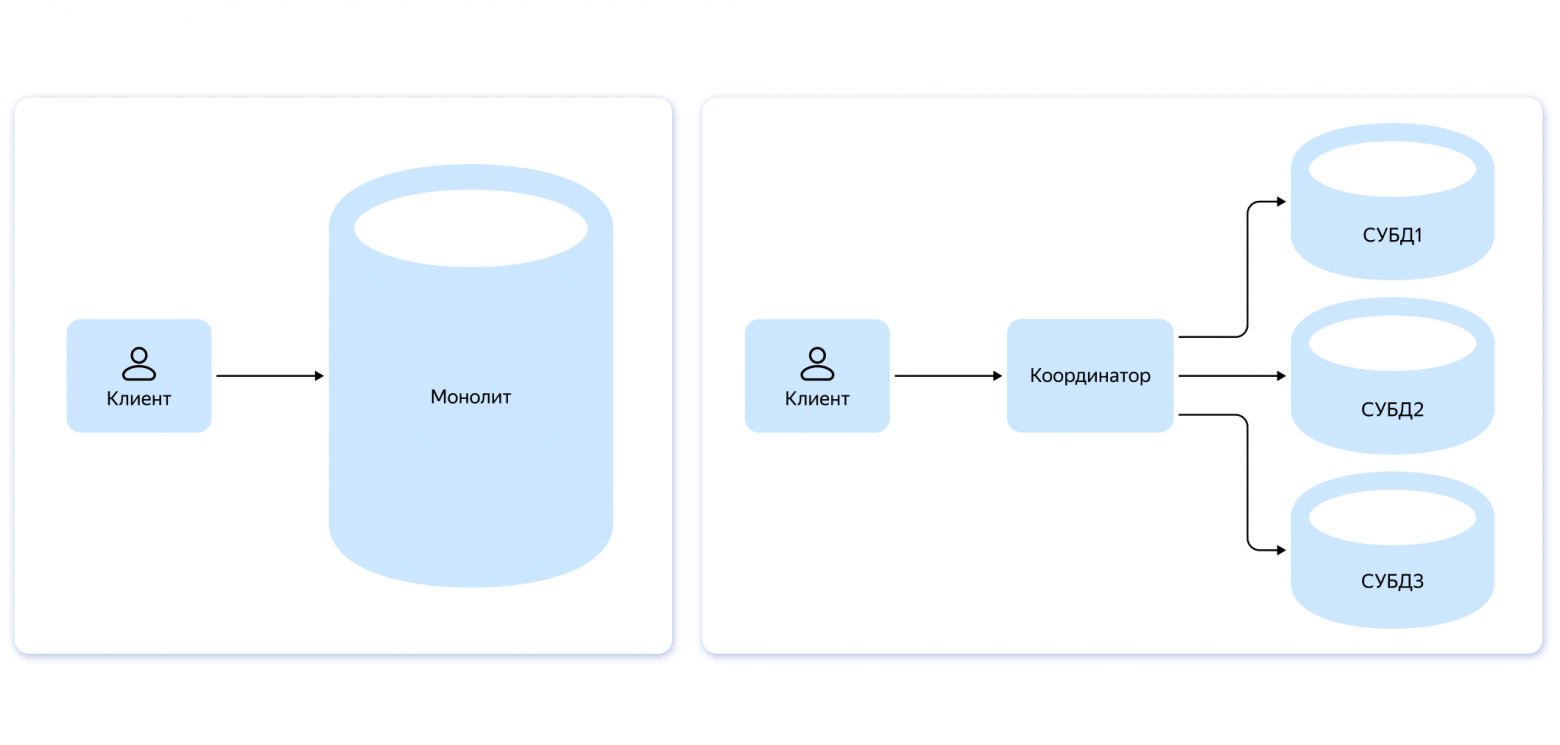
For users, nothing changes when transactions affect only one shard. However, multi-shard transactions receive weaker isolation guarantees than the monolith. This is fundamentally different from distributed databases, where guarantees do not depend on the number of affected shards.
ACID Properties and Two-Phase Commit
Transactions in databases are expected to have ACID properties:
Atomicity: All parts of the transaction either commit fully or are aborted entirely.
Consistency: Historically added to complete the acronym. A transaction transitions the system from one valid state to another according to rules (integrity constraints, triggers). In practice, this is often interpreted at the application level — the database merely provides the tools.
Isolation: Concurrent transactions do not affect each other. Changes from one transaction become visible to others only after successful completion. Results must appear as if transactions executed serially. Many databases support weaker isolation levels.
Durability: Successfully written data is never lost.
Martin Kleppmann in his book "Designing Data-Intensive Applications" suggested calling this property "Abortability," as it better reflects the essence: "all or nothing."
A critical distinction: "Atomicity" describes the behavior of a single transaction. "Isolation" concerns the interaction between transactions.

Two-phase commit (2PC) is an atomic commit protocol: upon completion, either all participants have applied the changes, or all have aborted. However, there are no guarantees of atomic visibility. Even if all nodes agree, there is no guarantee that changes become visible simultaneously or appear as a single operation.
Example: Alice, Vasya, and Bank Accounts
The database stores information about Alice's two accounts (X and Y), each on a separate shard. The initial balance is 100 rubles in each. Alice transfers 50 rubles from account X to account Y. The transaction uses 2PC with read-committed isolation.
Meanwhile, Vasya checks the total balance and sees 150 rubles instead of 200.
What happened: The first shard had already received the commit, so Vasya's transaction read 50. The second shard had not yet received the commit and returned the original value of 100. Result: 150, though three values are possible (150, 200, 250). Eventually, consistency converges to 200.
Conclusion: The absence of a distributed snapshot means the effective isolation level is "read committed."
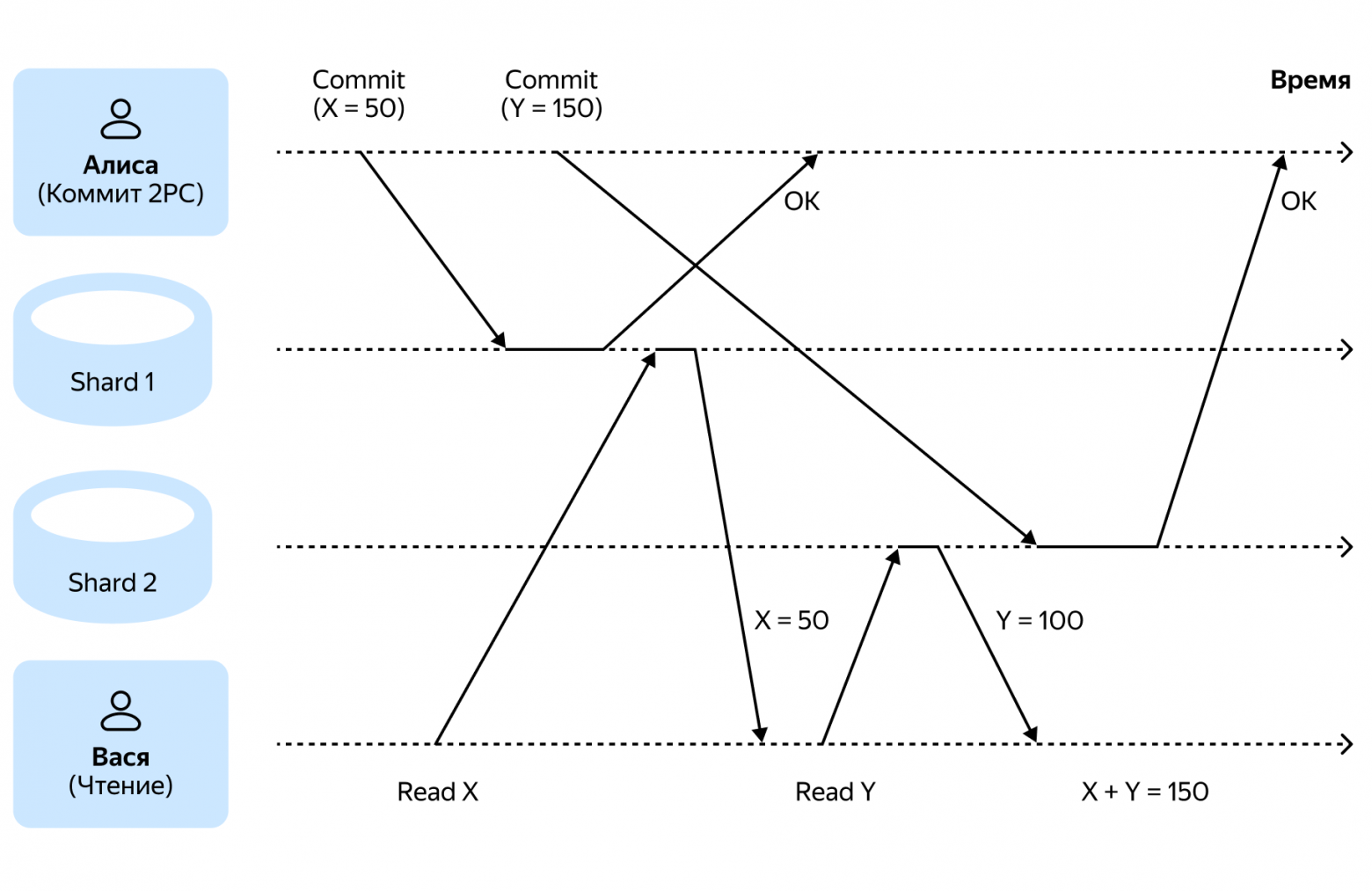
2PC achieved commit atomicity, but when describing the interaction between transactions, isolation questions arise where 2PC is powerless.
Multi-Shard Transactions in Citus Are Not ACID
Citus is a popular PostgreSQL extension for sharding. It is easy to install and use. However, the extension transforms PostgreSQL into a different type of database with different guarantees: everything works well if the transaction affects one shard, or if consistency in multi-shard operations is not critical.
We are not the first to write about this. We recommend these articles:
- Franck Pachot: "Citus is not ACID but Eventually Consistent"
- Franck Pachot: "How ACID is Citus? (compared to YugabyteDB)"
- Denis Magda: "Sharded Does Not Imply Distributed"
What the Citus Authors Say About Multi-Shard Transactions
In the paper "Citus: Distributed PostgreSQL for Data-Intensive Applications," the following is stated:
"3.7.4 Trade-offs in multi-shard transactions. Multi-shard transactions in Citus provide guarantees of atomicity, consistency, and durability, but do not provide distributed snapshot isolation. A concurrent multi-shard query may obtain a local MVCC snapshot before commit on one shard and after commit on another. To address this would require changes to PostgreSQL to make the snapshot manager extensible."
This explains why Vasya could not correctly calculate the total balance across different shards.
In the Citus documentation under "Table Management / Limitations," the only note is: "No support for serializable isolation level," with no mention of other levels or multi-shard operations.
The addition of the ability to specify isolation levels (in version 11.2) introduced confusion. Only the Release Notes clearly explain that by default, Citus uses "Read Committed":
"By default, when multiple shards participate in a transaction, Citus always sets the isolation level of the remote transaction to BEGIN TRANSACTION ISOLATION READ COMMITTED."
A further clarification in the Release Notes:
"Note that this does not mean that Citus supports full repeatable read or serializable semantics for all workload types."
Consistent Backup Mechanism in Citus
Citus supports periodic creation of consistent recovery points by writing to the WAL of each node. The point is created by locking writes to the coordinator's commit table, which prevents commits of in-flight 2PC transactions. According to the description, launching a backup can noticeably affect performance (the authors did not test this).
Why Citus Is Designed This Way
The architecture paper explains the trade-off:
"Existing methods for implementing distributed snapshot isolation have significant performance overhead due to the need for additional network round trips or clock synchronization, which increases response time and reduces throughput. In the context of PostgreSQL's synchronous protocol, throughput is limited to: number of connections / response time. Creating a large number of connections is often impractical, so low response time is the only way to achieve high throughput. If we implement distributed snapshot isolation, we will likely make it optional."
The Seattle Report on Database Research 2022
"There is an ongoing tension between two schools of thought: (a) In systems with high throughput and requirements for high availability and low latency, scaling distributed transaction processing is difficult without sacrificing traditional guarantees. Consistency and isolation are weakened, complicating application development. (b) The complexity of building correct applications without strong consistency and isolation is extremely high. The system should provide better throughput, availability, and latency without sacrificing correctness. This tension is unlikely to end, and the industry will continue to offer systems of both types."
Critical bugs caused by weak isolation levels are a common occurrence. The question is: in which cases is it truly justified to sacrifice database consistency for performance and complicate application development?
The Cost of Distributed Transactions
Transaction execution time in databases is typically measured in RTT (Round Trip Time) between hosts and I/O operations. NVMe has reduced the importance of the latter.
Scenarios:
- PostgreSQL without synchronous replication: 0 RTT
- PostgreSQL with synchronous replication: 1 RTT
- Citus (base): 3 RTT
- Citus with 2PC: 3 + 2 = 5 RTT
- YDB (distributed database): 4.5 RTT + 0.5 ms for planning and batching
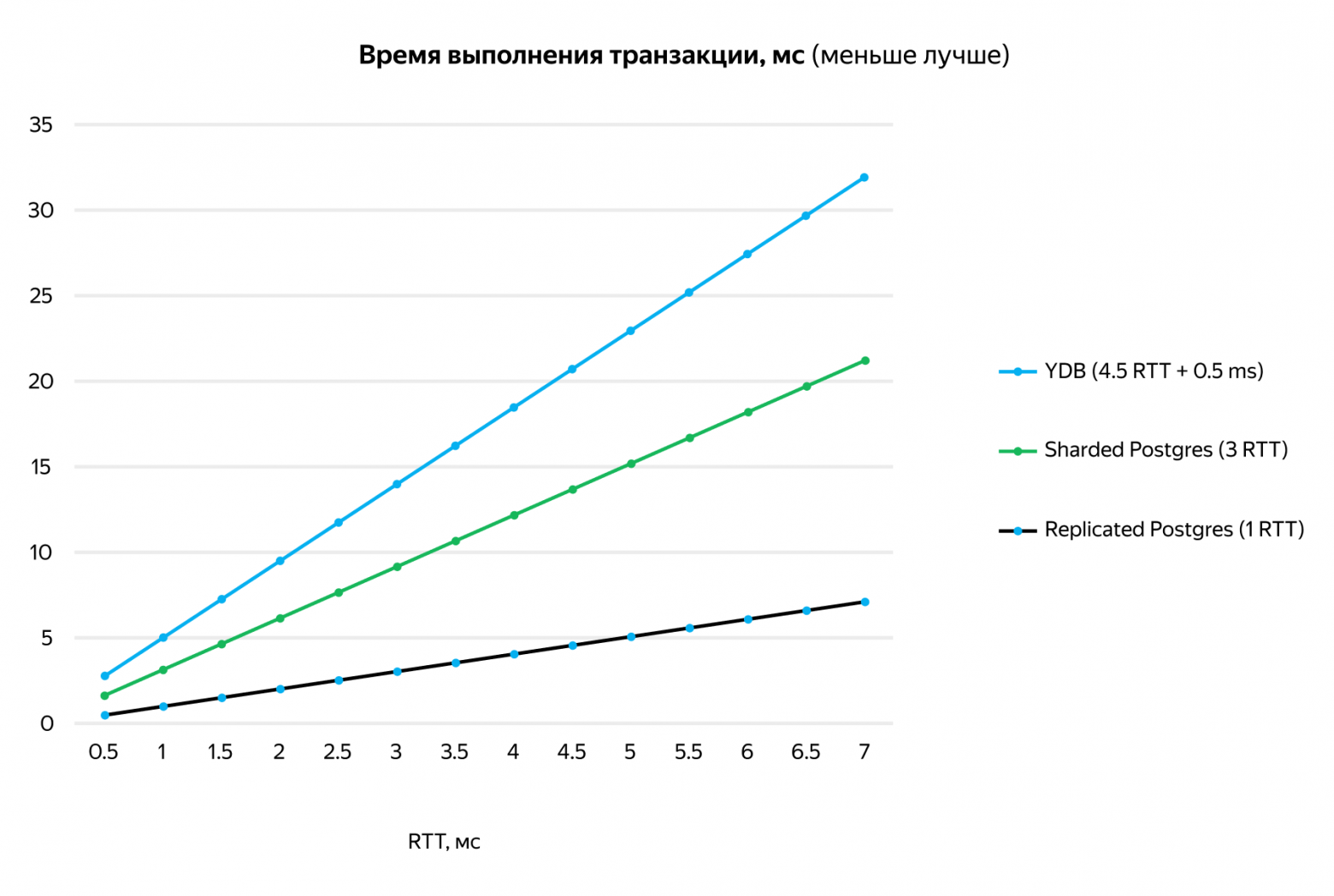
In practice, everything depends on the RTT value. Within a single data center, RTT is negligibly small. When using multiple availability zones (closely located data centers), RTT is measured in hundreds of microseconds or single-digit milliseconds.
At an RTT of 7 ms, the difference between Citus and distributed databases is only 10 ms. Transaction execution time for both types does not exceed 50 ms, which is sufficient for most applications.
The question remains: Is it worth sacrificing correctness guarantees (consistency) provided to applications by the database for such a small gain?
Conclusion
PostgreSQL is an excellent and extremely efficient database. As load grows, at some point its performance becomes insufficient. You face a choice between sharded PostgreSQL and a distributed database.
The key difference: Citus-like solutions in the case of wide (multi-shard) transactions are typically not ACID and do not provide the same guarantees as standalone PostgreSQL.
Not all applications need both wide transactions and strict guarantees (unlike banks). However, distributed databases provide ACID for any transactions and are much more efficient than commonly believed. They deserve attention if PostgreSQL becomes a bottleneck.
Acknowledgments: This article was inspired by publications and talks by Franck Pachot and Denis Magda. The authors express gratitude to Evgeny Efimkin (PostgreSQL expert) and Andrey Borodin (PostgreSQL contributor).
FAQ
What is this article about in one sentence?
This article explains the core idea in practical terms and focuses on what you can apply in real work.
Who is this article for?
It is written for engineers, technical leaders, and curious readers who want a clear, implementation-focused explanation.
What should I read next?
Use the related articles below to continue with closely connected topics and concrete examples.





