The Go Scheduler: The Most Detailed Guide in Plain Language
This article walks through designing Go's scheduler from scratch, starting with the simplest implementation and progressively adding optimizations like work stealing, handoff, and preemption.
Concurrency is very useful, but very complicated. In this article, we'll design a scheduler step by step, starting from the simplest possible implementation and gradually adding optimizations — exactly the way the creators of Go did it. The three key entities we'll work with are goroutines, the scheduler, and channels.
Parallelism vs. Concurrency
Concurrency is a program design with independent processes. Parallelism is simultaneous execution on different cores. As Rob Pike put it: "Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once."
A thread can be in one of three states:
- Executing — currently running on a CPU core
- Runnable — ready to execute, waiting for a free core
- Waiting — blocked, waiting for some event (I/O, mutex, etc.)
Stage 1: The 1:1 Model
The simplest approach: create a separate OS thread for each goroutine. When you call go func(), the runtime creates a new thread, runs the function, and destroys the thread when it finishes. This is simple but extremely inefficient — creating and destroying OS threads is expensive (each thread requires ~1MB of stack memory), and context switching between threads is slow because it involves the kernel.
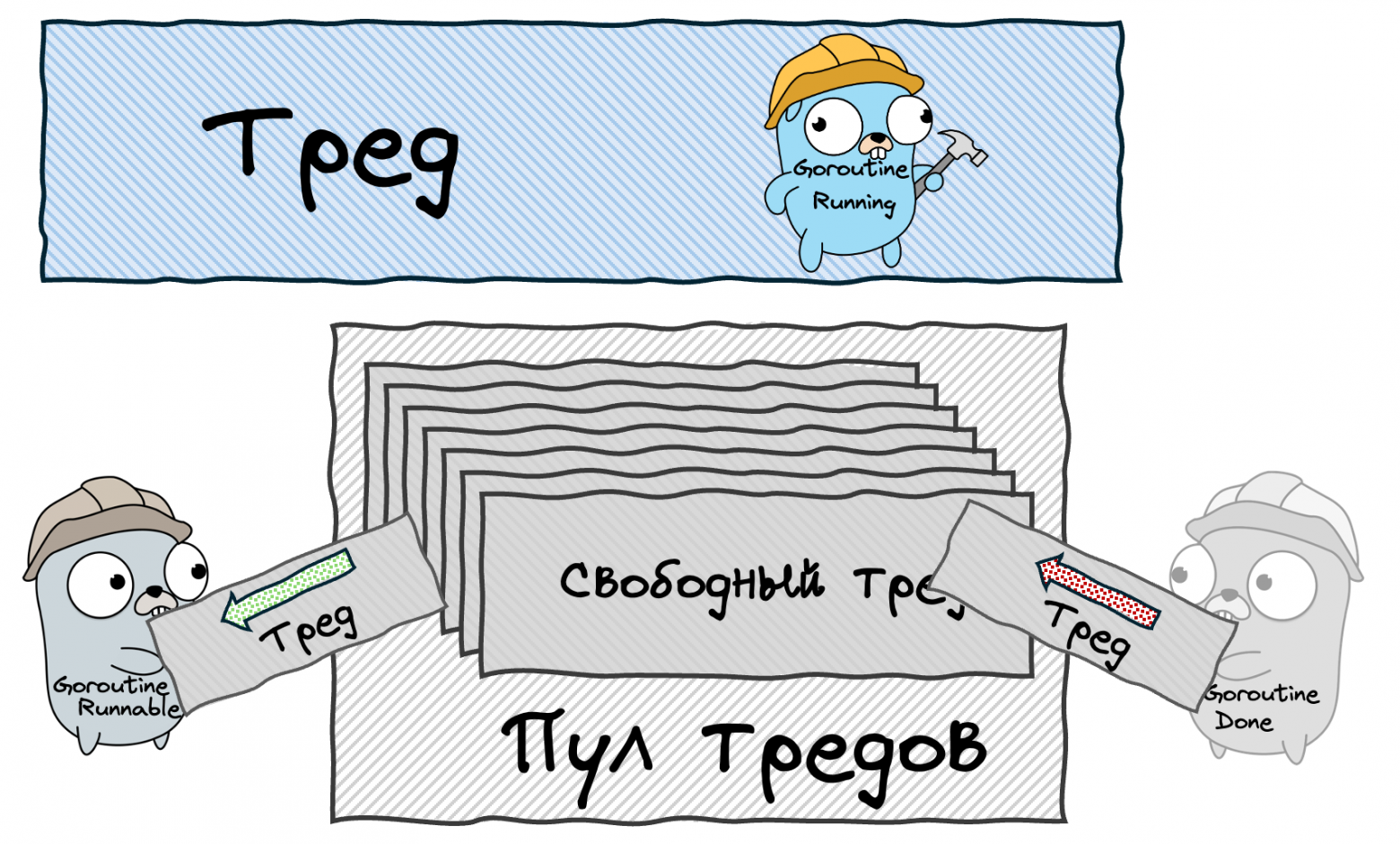
Stage 2: Thread Pool
Instead of destroying threads after a goroutine finishes, we keep them in a pool and reuse them. When a new goroutine is created, we take an idle thread from the pool instead of creating a new one. This eliminates the overhead of constant thread creation and destruction. But we still have a problem: if we create thousands of goroutines, we'll have thousands of threads, and the OS will waste a lot of time on context switching between them.

Stage 3: The M:N Model
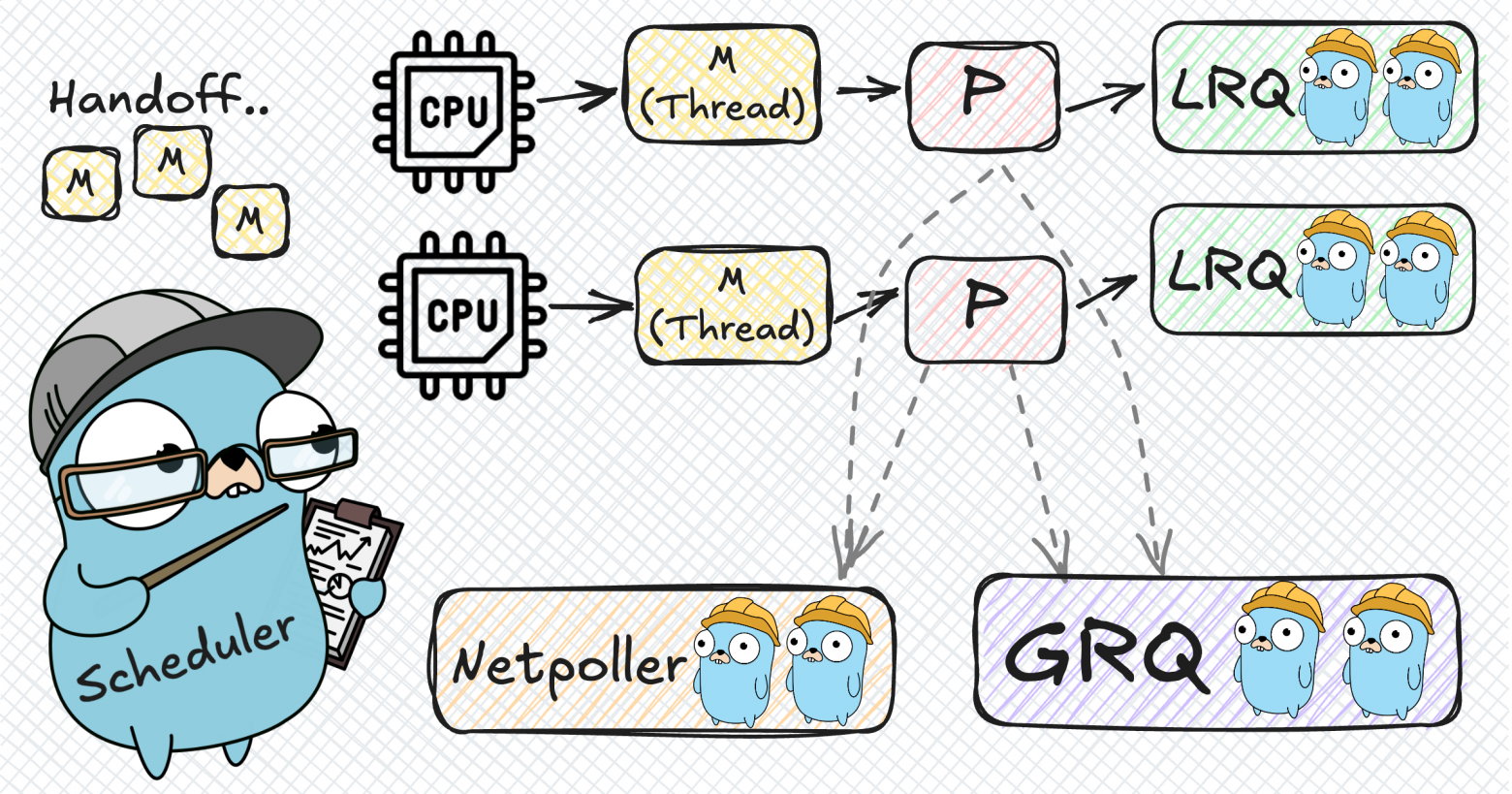
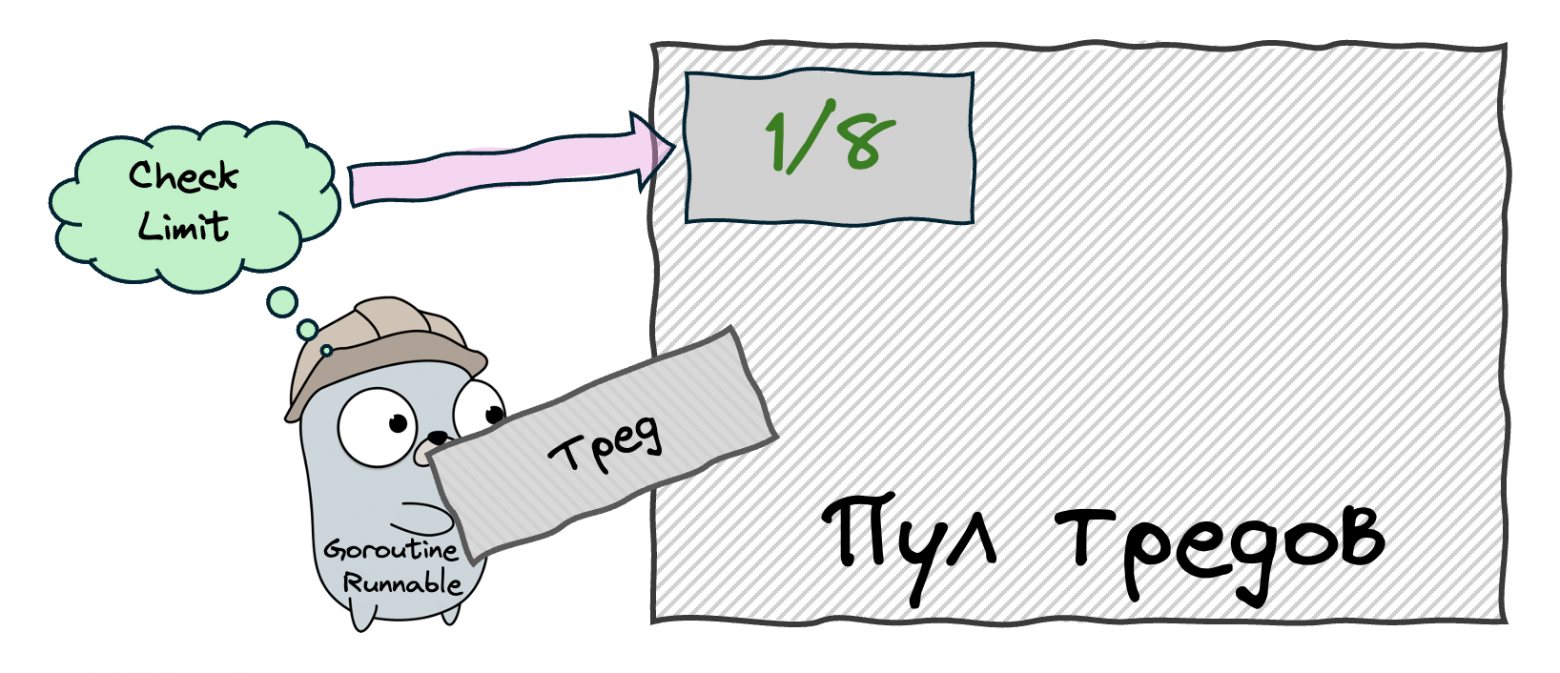
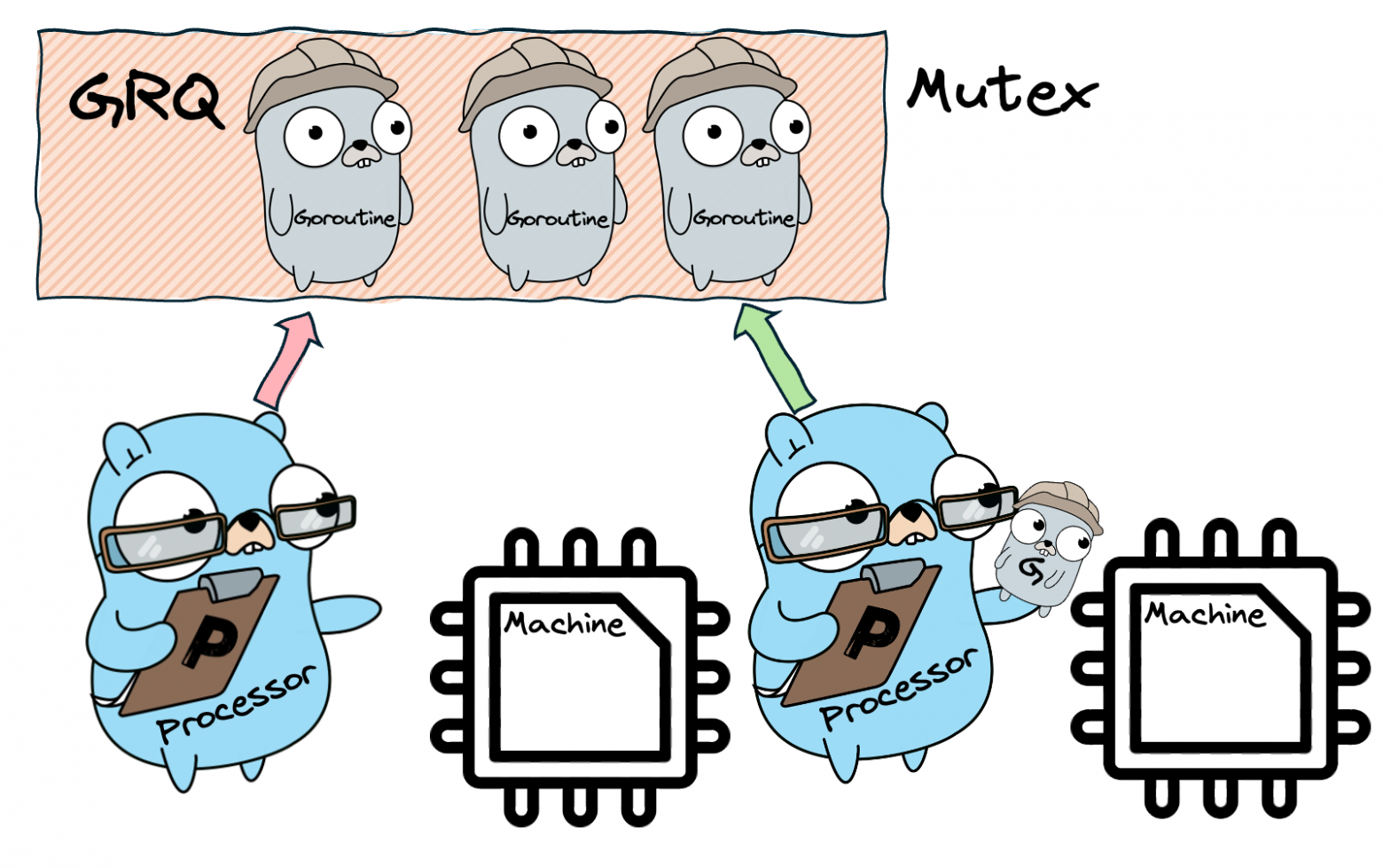
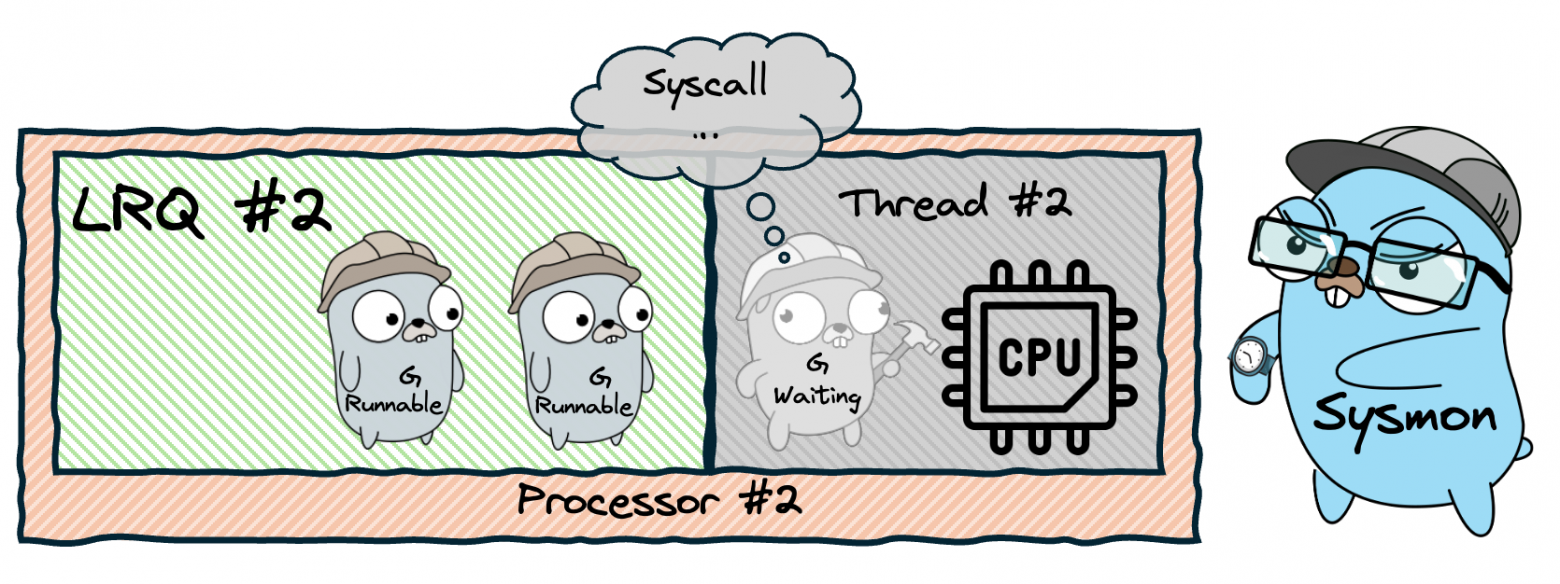
We limit the thread pool size to exactly the number of available CPU cores, creating an optimal ratio of N goroutines on M threads. Now we introduce an intermediary — the Processor (P). Each Processor is bound to one OS Thread (M) and manages the execution of goroutines (G). When a goroutine finishes or blocks, the Processor picks the next one from its queue. The number of Processors equals GOMAXPROCS, which defaults to the number of CPU cores.
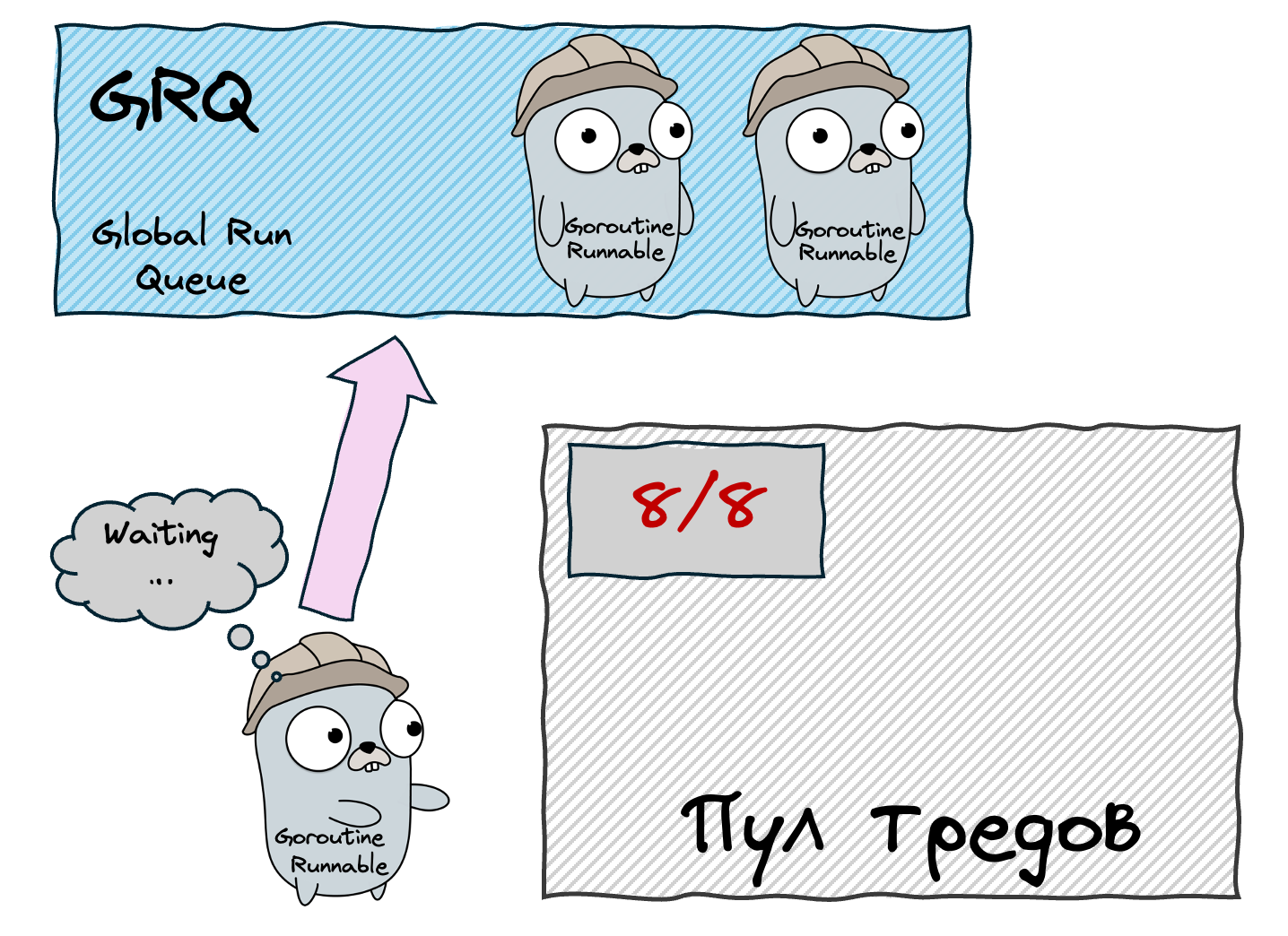
But where do new goroutines go? Initially, into a Global Run Queue (GRQ) — a shared queue protected by a mutex. This works, but the mutex becomes a bottleneck when many Processors compete for it.

Stage 4: Local Run Queues
To solve the GRQ bottleneck, we give each Processor its own Local Run Queue (LRQ). When a goroutine spawns a new goroutine, the child goes into the parent's Processor's LRQ — no mutex needed! The GRQ still exists as a fallback, but it's accessed much less frequently. Each LRQ is implemented as a lock-free circular buffer with a capacity of 256 goroutines. If the LRQ is full, half of its goroutines are moved to the GRQ.

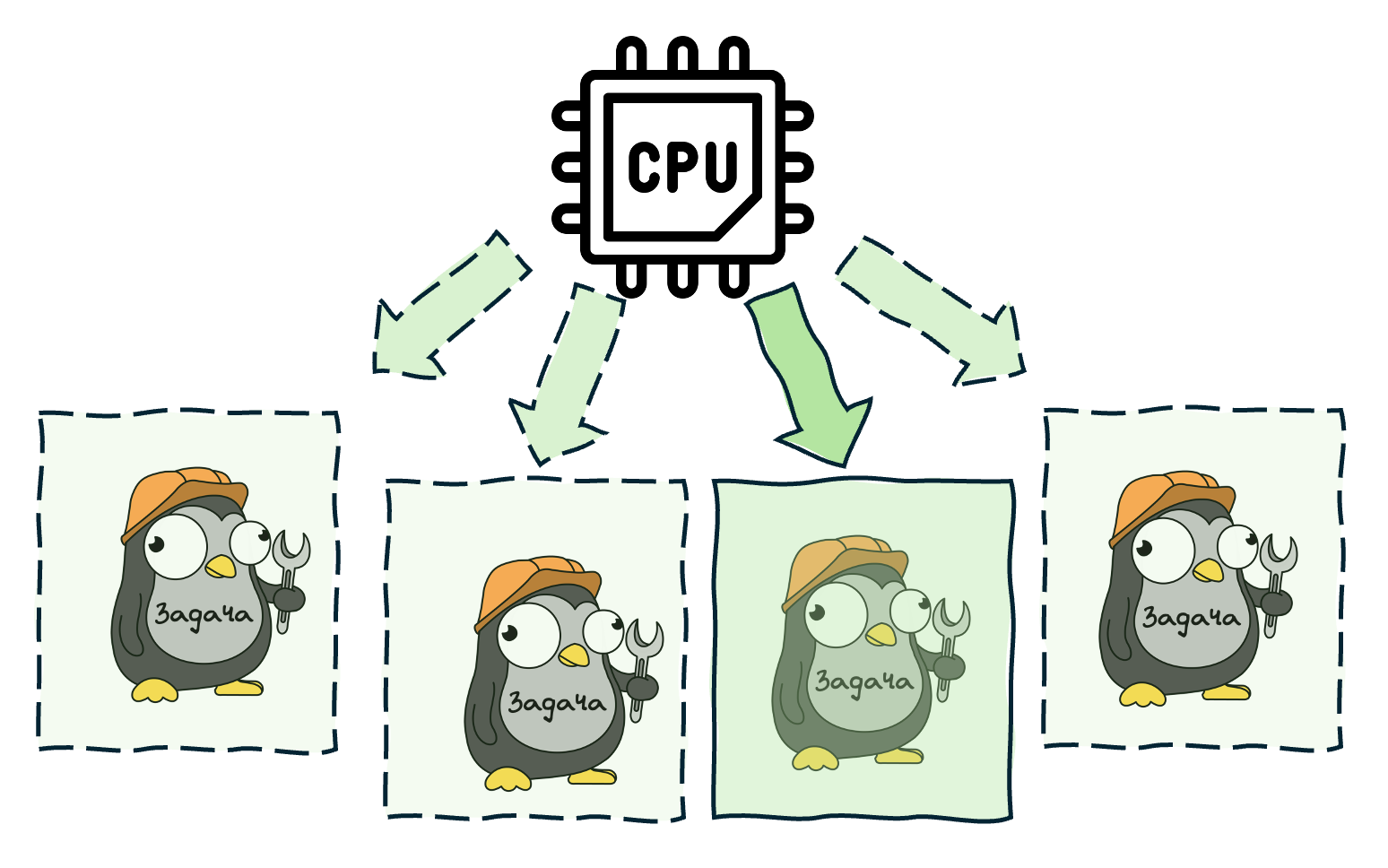
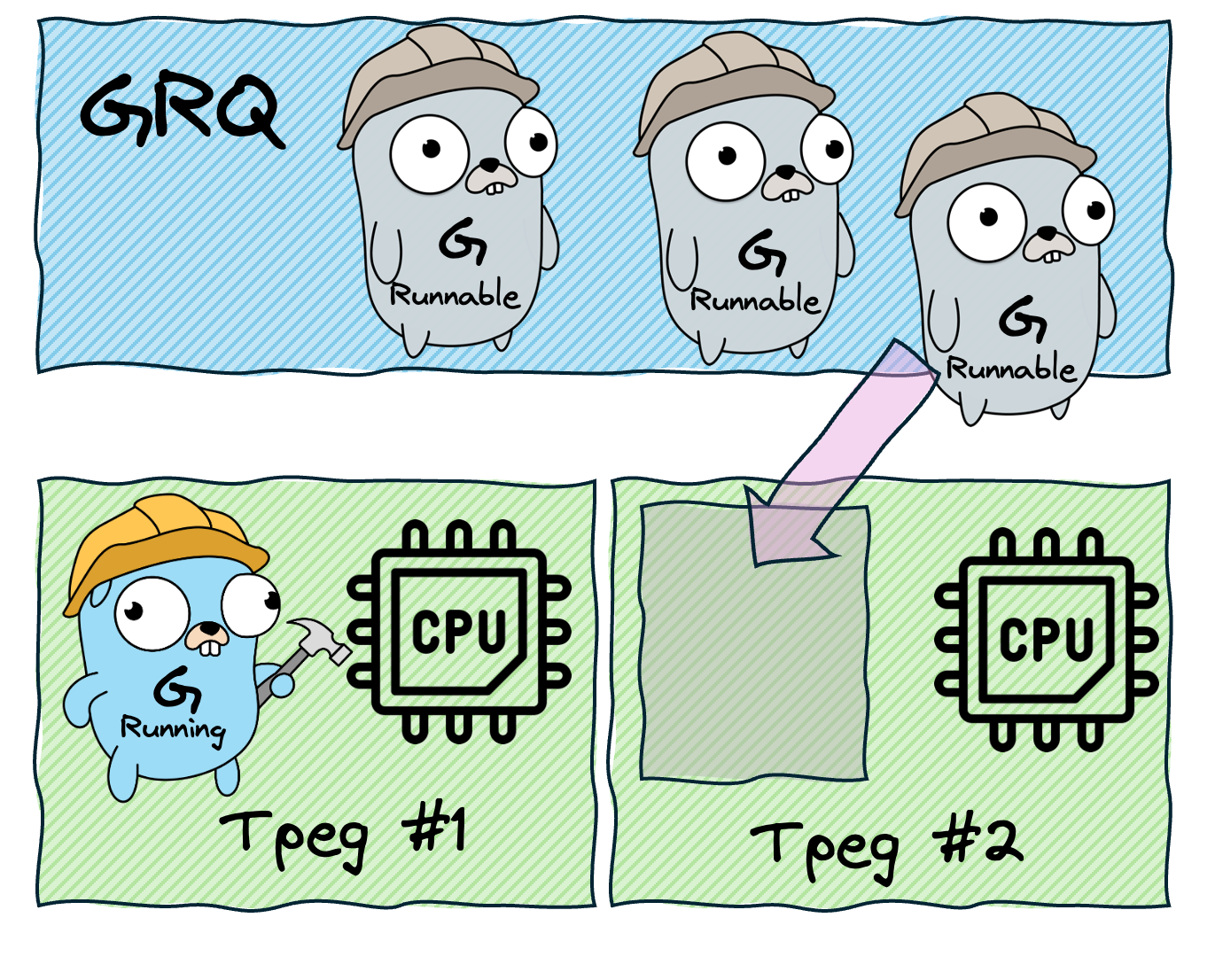
Stage 5: Work Stealing
What happens when a Processor's LRQ is empty? Instead of sitting idle, the Processor becomes a "thief." It looks into another Processor's LRQ and steals half of its goroutines. If all LRQs are empty, it checks the GRQ. This is the work stealing algorithm, and it ensures even load distribution across all Processors without centralized coordination.

The full order of operations when a Processor needs work:
- Check the local LRQ
- Check the GRQ
- Try to steal from another Processor's LRQ
- Check the network poller
Stage 6: Handoff
What happens when a goroutine makes a blocking system call (like reading a file)? The entire OS thread blocks, and the Processor attached to it can't run other goroutines. The solution is the handoff mechanism: when a thread is about to block, the Processor detaches from it and attaches to a new (or idle) thread. The blocked thread stays blocked with its goroutine. When the syscall completes, the goroutine is placed back in a queue, and the now-idle thread returns to the thread pool.
Stage 7: Network Poller
Network operations are special because the OS provides asynchronous interfaces for them (epoll on Linux, kqueue on macOS). Instead of blocking a thread for each network call, Go uses the Network Poller. When a goroutine makes a network call, it's parked in the netpoller, and the Processor moves on to the next goroutine. When the network operation completes, the poller wakes up the goroutine and puts it back in a run queue. This way, thousands of goroutines can wait for network I/O without blocking any OS threads.
Stage 8: Goroutine Preemption
What if a goroutine runs an infinite loop with no function calls? Without preemption, it would hog the Processor forever, starving other goroutines. Go solves this in two ways:
Cooperative preemption (before Go 1.14): The compiler inserts preemption checks at function prologues. Each goroutine has a stackguard field. A background thread called Sysmon monitors all goroutines, and if any has been running too long (~10ms), Sysmon sets its stackguard to stackPreempt. The next time the goroutine calls a function, the stack check fails, triggering a reschedule.

Asynchronous preemption (Go 1.14+): For goroutines that don't make function calls (tight loops), Go uses OS signals. On Unix systems, the runtime sends a SIGURG signal to the thread running the greedy goroutine. The signal handler pauses the goroutine at a safe point and reschedules it.
Sysmon: The Background Watchdog
Sysmon is a special goroutine that runs on its own dedicated OS thread, outside of any Processor. It performs several critical functions:
- Detects goroutines stuck in syscalls and triggers handoff
- Monitors long-running goroutines and sets preemption flags
- Periodically polls the network poller to ensure waiting goroutines are woken up
- Triggers garbage collection if needed
Putting It All Together
The final architecture of Go's scheduler consists of:
- G (Goroutine) — lightweight green threads with ~2KB initial stack
- M (Machine/Thread) — OS threads from the thread pool
- P (Processor) — logical processors, one per CPU core by default
- GRQ — Global Run Queue, a shared fallback queue
- LRQ — Local Run Queue, one per Processor, lock-free
- Network Poller — async I/O multiplexer
- Sysmon — background monitoring thread
Each of these components was added to solve a specific problem. The 1:1 model was too expensive, so we added thread pools. Thread pools with a global queue had lock contention, so we added local queues. Local queues could become imbalanced, so we added work stealing. Blocking syscalls wasted threads, so we added handoff. Network I/O was wasteful, so we added the network poller. Greedy goroutines could starve others, so we added preemption. And Sysmon ties it all together as the watchdog.
Thank you to everyone who read this article to the end — you've done tremendous work, and that deserves respect! For deeper analysis, I recommend the goschedviz utility which lets you visualize the scheduler's behavior in real time.



