Working with Terraform: Rules of Thumb
Since about 2018, I have been programming infrastructure, if not every day, then several times a week. I do not claim that this allows me to claim any authority. But during this time I definitely managed to form concrete opinions on some issues. In this article, I'll share some o
Editor's Context
This article is an English adaptation with additional editorial framing for an international audience.
- Terminology and structure were localized for clarity.
- Examples were rewritten for practical readability.
- Technical claims were preserved with source attribution.
Source: original publication
Since about 2018, I have been programming infrastructure, if not every day, then several times a week. I do not claim that this allows me to claim any authority. But during this time I definitely managed to form concrete opinions on some issues. In this article, I'll share some of these observations as rules of thumb that I try to follow when developing for Terraform, but you can just as easily apply them in other infrastructure programming languages.
1. Don't sacrifice local development
This is a true flagship, so if I had to leave just one item, it would be this one!
In my experience, such sacrifice comes in two forms. First, strict dependencies on the environment in which the pipelines are executed are allowed. For example, token replacement tools are used instead of normal Terraform variables, or common modules are copied into a directory for deployment at runtime. This happens when Terraform is deployed for the sole purpose of being used in a pipeline.
In fact, pipelines are needed to deploy changes to real environments. But to do this, you should not build a system in which the engineer would not be able to test and debug the system being created, in whole or in part, directly on his computer. If the system runs locally, then it can run in a pipeline, but the opposite is not always true. Don't let it happen git commit && git push && *вечно дожидаться, пока конвейер сообщит вам об опечатке* was the only way to test the change.
Another option for completely abandoning local development is the abuse of the generalized vocabularies provided in terraform (maps) using them as modular variables. If the module is designed for all its contents to be transferred to map(string) — and I’ve come across this quite often—everyone who deals with such variables, both developers and users, works blindly, without any type hints at the IDE or validation level. This approach grossly distorts the good old familiar development on a local machine.
Sometimes you can’t do without dynamic dictionaries—for example, when working with resource tags. But, if you know what parameters your module will need, define them as separate variables or as object with known attributes.
### Не делайте так variable "subnet_config" { type = map(string) } resource "subnet" "mySubnet" { name = var.subnet_config["name"] ... } ### А делайте так variable "subnet_config" { type = object({ name = string cidr = string
In the first example we are flying blind. In the second example, a terraform-like system (no, this is not a type of copilot) helps us as a co-pilot. If this seems so obvious to you that it doesn’t even need explanation, believe me, it does.
2. Consider who your audience is
When developing a terraform module, keep in mind who it is being made for. Sometimes the target audience is platform engineers or infrastructure engineers, and these people often value the ability to see the system in great detail and control their configuration. If you hide these details from users, they may not like it.
Programmers, in turn, value the ability to get infrastructure up and running as quickly as possible, so that they have to make as few decisions as possible. Your module will be more popular if you can minimize the time during which the programmer will have to be distracted from everyday work. For such people, try to limit the required parameters as much as possible, and for all other parameters, provide reasonable omissions.
3. Try to use modules to reduce the complexity of common patterns
“Compressing complexity” is a term seen in Ruby on Rails community. The technique itself is an option for creating balanced abstractions that do not hide complexity, but still not too much of a headache for the person who has to manage them. When applied to terraform modules, this practice allows minimizing mandatory parameters, but at the same time provide sufficient quantities optional parameters with reasonable and consciously chosen defaults. If the complexity is well compacted in the module, then it is easy for the developer to start working with it, since he does not have to thoroughly understand the module. However, it remains possible to override the defaults if more complete control over the module is needed. .
Learning to approach modules this way will come in handy when you start packaging resources and other modules into higher-level packages. Such composite modules can contain useful abstractions that describe platform patterns that make sense in the particular domain in which you work. Gregor Hop explained this concept perfectly using the following example from the financial sector. The user defines a database called "ledgered-database" in which a number of AWS services are compiled and configured, which in turn are highly reusable. Users of such a module do not need to know anything about a specific database or event routing technologies - and, nevertheless, they can quickly implement such functionality into their application. Other examples include
feature-storefor managing and providing features in machine learning. These may include services for data storage, ensuring the operation of pipelines, versioning and API hosting.workflow-orchestratorto define and manage business task flows. These may include services for managing queues, triggers, status, and observability.policy-enforced-apifor hosting secure API services, including API gateway, authentication, policy compliance (such as rate limiting policies), monitoring, encryption, and standards compliance.
These types of modules are very valuable, so don't miss out on opportunities to create them. But keep in mind that they are only useful if they are actively used - so here's another reason for you to carefully consider how the user will perceive them. You don't want to get into trap of competing standards!
4. Structure terraform code using modules, stacks, and deployment units
Here I come to the urgent instructions. As your terraform codebase grows, you have to think about how to structure it. This structure is based on three top-level directories and, in my experience, works really well. I will describe these directories:
modules: Contains small modules that describe individual resources or combinations of individual resources that provide, for example, data transfer on a private network or credential management.stacks: Contains relatively large modules in which solutions are built from smaller modules (this is where you may encounter one of those high-level modules discussed in the previous section). Stacks contain the complexity of the relationships between different resources, and often contain code that simplifies the interactions between those resources. For example, this could be code for creating secrets, assigning roles, etc. Stacks also control what variations are available in different environments—exactly as many variables as needed are provided.deployments: consumes stacks and represents individual ones instances or environment specific stack. This is where you will find the backend and provider configurations for terraform, as well as any details that may differ from environment to environment (such as parameter names or sizes).
As a result, you will end up with something like this structure:
terraform/ ├── modules/ │ ├── app_service/ │ ├── sql_database/ │ ├── storage_account/ │ ├── virtual_network/ │ └── key_vault/ ├── stacks/ │ ├── app1/ │ └── app2/ │ └── shared_service/ ├── deployments/ │ ├── app1/ │ │ ├── dev/ │ │ ├── test/ │ │ └── prod/ │ └── app2/ │ ├── dev/ │ ├── test/ │ └── prod/ │ └── shared_service/ │ ├── dev/ │ ├── test/ │ └── prod/
Here's a visual representation:
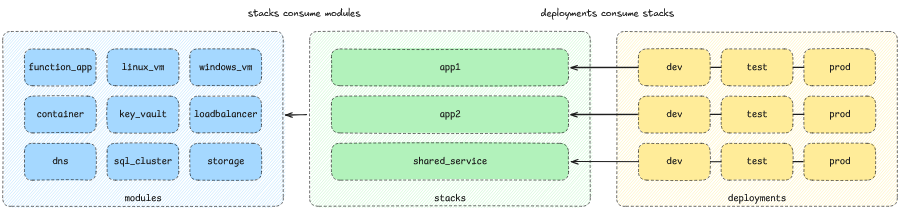
Please note: Recently, Hashicorp, in beta testing mode, rolled out a new feature called “stacks” for its cloud version of Terraform. It has nothing to do with the “stacks” that I write about in this section, although conceptually the first and second “stacks” are very similar.
By adopting this structure, you can maintain a clean, scalable infrastructure code base that developers can understand. It will make it easier for you to manage complex infrastructures and help you reuse the same code across different projects.
That's all for now. Just remember: infrastructure code can must be developer friendly!
News, product reviews and competitions from the Timeweb.Cloud team — in our Telegram channel ↩

📚 Read also:
➤ Three Terraform use cases you should start implementing
➤ Splitting Terraform files into composable layers
➤ How to parse data with Python
➤ New ECMAScript Features - Import Attributes and Regular Expression Pattern Modifiers
➤ In-process system call tracing using chained loader
Why This Matters In Practice
Beyond the original publication, Working with Terraform: Rules of Thumb matters because teams need reusable decision patterns, not one-off anecdotes. Since about 2018, I have been programming infrastructure, if not every day, then several times a week. I do not claim that this allows me to...
Operational Takeaways
- Separate core principles from context-specific details before implementation.
- Define measurable success criteria before adopting the approach.
- Validate assumptions on a small scope, then scale based on evidence.
Quick Applicability Checklist
- Can this be reproduced with your current team and constraints?
- Do you have observable signals to confirm improvement?
- What trade-off (speed, cost, complexity, risk) are you accepting?



